
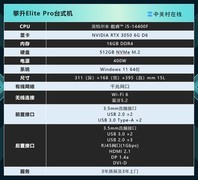
当模型参数突破亿级,当数据集加载耗时成为瓶颈,当本地验证需要毫秒级响应——AI开发者与研究人员正迫切呼唤一套兼具精度、带宽、稳定性和可扩展性的图形计算底座。他们不只需要游戏帧率,更需要CUDA核心密度、显存带宽利用率、FP16张量加速能力以及长期满载下的散热冗余。在这一语境下,显卡早已超越显示输出设备的原始定义,演化为神经网络训练、推理部署与算法原型验证的核心协处理器。
昂达GT1030典范4GD4-V以699元的亲民价格切入,虽定位入门,却凭借14纳米工艺、384个CUDA核心与2100MHz GDDR4显存频率,在轻量级图像预处理、小规模YOLOv5微调及Jupyter Notebook本地调试等场景中展现扎实能效比;其单风扇紧凑结构适配各类嵌入式工控机与老旧主机升级,是学生研究者与初创团队构建低成本实验节点的理想选择。
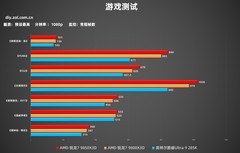
影驰GeForce RTX 2080 SUPER HOF Classic以5999元锚定专业性能标杆,搭载完整TU104核心与8GB GDDR6显存,支持实时光线追踪与第三代Tensor Core,在ResNet-50单卡训练、Stable Diffusion v2.1文生图批量生成及Blender Cycles渲染中展现出极高的吞吐稳定性;其HOF经典版堆料设计与金属背板强化了7×24小时持续训练的可靠性,是高校实验室与中小AI企业部署关键模型训练任务的硬核之选。
铭瑄RTX 2070 SUPER iCraft OC 8G以3549元实现性能与成本的精妙平衡,OC超频设定使GPU Boost频率稳定在1785MHz以上,配合双8mm热管+四热鳍散热模组,在BERT-base微调与OpenMMLab系列检测模型训练中保持低温低噪;对预算有限但需承载中等规模Transformer训练的工程师而言,它提供了接近旗舰的算力弹性与更低的TCO(总体拥有成本)。
发行者RX5700 8GB标准版以799元提供AMD阵营的高显存容量优势,虽CUDA生态兼容性弱于NVIDIA系,但在ONNX Runtime推理、传统CV算法加速及OpenCL异构计算验证中仍具实用价值;其8GB显存对特征缓存、多路视频流解码与轻量级GAN训练形成有效支撑,适合跨平台技术验证与教学演示场景。
索泰RTX 2060 SUPER-8GD6至尊PLUS OC以3399元成为高性价比主力型号,GDDR6显存带宽达448GB/s,支持CUDA 10.2及以上全版本框架,在PyTorch分布式DataParallel模式下表现出色;其定制PCB与强化供电设计保障了长时间梯度反传的电压稳定性,是个人AI工作站与远程云训练节点最具普适性的核心配置。
从百元级轻量推理到万元级全模态训练,这五款显卡共同勾勒出AI开发者在不同阶段、不同预算、不同部署环境下的真实算力光谱。它们未必拥有最炫的灯效或最强的单点跑分,却在编译兼容性、驱动成熟度、显存带宽分配逻辑与长期运行衰减控制上,默默支撑着每一次loss下降与accuracy跃升。











































































































评论
更多评论