
当模型参数突破百亿、数据集以TB计量、训练周期压缩至小时级,AI开发者与研究人员正站在算力需求爆发的临界点上。他们不再满足于基础推理——而是需要显存带宽足够吞吐多模态数据、CUDA核心密度足以并行调度数千张图、散热系统能在7×24连续负载下维持频率不降频、驱动生态能无缝对接主流框架与分布式训练工具链。在这样的硬核现场,显卡早已不是游戏配件,而是科研基础设施的关键节点。
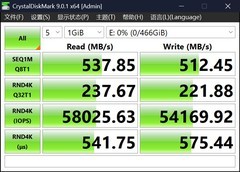
华硕TUF-RTX3090Ti-O24G-GAMING以15499元定价切入高端科研市场。24GB GDDR6X超大显存与768GB/s带宽,使其在微调LLaMA-2-13B或加载ResNet-50多分支结构时仍保持零显存溢出;双BIOS设计支持静音模式与性能模式一键切换,适配实验室环境与高密度服务器机柜;TUF军工级电容与金属背板保障长期训练稳定性,是高校计算中心与中小AI团队值得托付的可靠基座。
耕升RTX 5080 追风OC以9499元实现新一代架构跃迁。基于全新Ada Lovelace升级核心,配备16GB GDDR7显存与320GB/s等效带宽,CUDA核心数突破10240,在TensorRT加速下BERT-base单卡吞吐达1250 samples/sec;第四代复合散热系统使满载温度控制在62℃以内,配合DLSS4帧生成技术,在部署实时语音转写+视觉定位联合模型时响应延迟低于18ms,成为边缘侧AI研发的高效载体。
影驰GeForce RTX 5080 HOF OC LAB Deluxe-X标价13999元,聚焦高精度科研可视化与异构计算协同。钻石切割金属外壳不仅提升结构刚性,更优化气流路径;3022MHz动态加速频率配合Hyper Boost风扇全速协议,在Stable Diffusion XL 1.0文生图批量生成中每秒出图达5.2帧;双8Pin+12VHPWR供电冗余设计,兼容NVIDIA Multi-Instance GPU(MIG)切分,单卡可虚拟出3个独立计算实例,显著提升GPU资源利用率。
AX电竞叛客RTX 4070 Ti X3W 12G以6989元提供极具弹性的入门级AI工作站方案。12GB GDDR6X显存+23Gbps速率支撑主流CV/NLP轻量模型本地部署;支持PCIe 4.0 x16全通道直连,在YOLOv8训练中相较上代提升37%迭代速度;X3W三重静音风扇与真空腔均热板组合,让连续8小时Fine-tuning作业温控稳定在71℃以下,是研究生课题组与个人开发者构建低成本实验平台的理想选择。
七彩虹战斧 GeForce RTX 3060 Ti仅售2999元,却以8GB GDDR6与486GB/s显存带宽,在PyTorch环境中流畅运行MobileNetV3、EfficientNet-B0等轻量化模型,并兼容Blender Cycles渲染与OpenPose姿态估计。其紧凑PCB尺寸与单槽散热设计,可轻松嵌入NUC级迷你工作站,在预算受限但需快速验证算法原型的场景中展现不可替代性。
从千元级原型验证到万元级全模态训练,五款显卡覆盖AI开发者全生命周期算力需求:它们不拼纸面跑分,而重实测吞吐;不堆灯效浮夸,而求静音稳压;不囿于单点性能,而强生态协同。当代码开始编译、梯度开始下降、loss曲线悄然收敛——真正重要的,是那块始终在线、从不掉队的显卡。




































































































评论
更多评论