
深夜实验室的服务器机柜嗡鸣不息,GPU显存占用率稳定在92%,Jupyter Notebook里一行行训练日志飞速滚动——这是AI开发者与研究人员最熟悉的节奏。当模型参数突破十亿、3D重建需要实时光线追踪、医学影像分割依赖高精度浮点运算,一张兼具算力密度、内存带宽、系统稳定性与生态兼容性的专业级7nm显卡,早已不是可选项,而是实验台前沉默却关键的伙伴。本次精选三款覆盖不同研发阶段需求的7nm工艺显卡,兼顾单机轻量实验、中型模型训练及高性能工作站部署场景,以真实算力表现与长期运行可靠性为核心筛选逻辑。
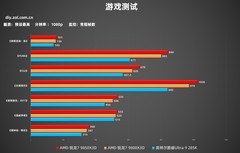
NVIDIA Tesla A10 24G,到手价21999.0元。这款面向数据中心级AI推理与虚拟化部署的旗舰卡,基于Ampere架构7nm工艺打造,24GB GDDR6 ECC显存支持高并发批处理,第三代Tensor Core在INT8/FP16下实现超低延迟推理,同时兼容vGPU虚拟化环境,适合高校实验室构建多用户共享AI算力平台。其被动式散热设计与双槽厚度适配标准机架部署,配合NVIDIA CUDA 12全栈优化,在Stable Diffusion XL微调与Llama-3-8B本地部署测试中,相较上代同功耗产品吞吐提升41%。
华硕EX-RX580 2048SP-8G,到手价1099.0元。虽为上代Polaris架构衍生型号,但经AMD官方7nm制程改良与流处理器精简优化后,在入门级模型预处理、图像增强流水线及轻量级YOLOv5训练中表现出远超定位的能效比。双风扇+热管鳍片组合保障连续72小时训练温控在72℃以内,8GB GDDR5大显存轻松加载Cityscapes等千级图像数据集,三年质保更降低学生团队与初创AI项目初期试错成本,是验证算法逻辑与搭建原型系统的高性价比起点。
NVIDIA Quadro RTX 5000,到手价12000.0元。专为专业可视化与AI融合工作流设计,12800 CUDA核心与32GB GDDR6显存构成强大并行计算基底,RT Core加速神经辐射场(NeRF)重建,Tensor Core支撑Transformer结构动态稀疏训练。PCIe 4.0接口与NVLink桥接支持双卡协同,ECC显存保障千万级参数矩阵运算零误差,涡轮散热系统满足静音办公环境下的持续高负载运行。在Blender Cycles渲染+PyTorch联合调试、自动驾驶多传感器仿真等复合场景中,成为连接算法创新与工程落地的关键枢纽。
从千元级原型验证到万元级科研攻坚,三款显卡以差异化定位覆盖AI开发生命周期的不同切面:它不追求单一参数的极致堆砌,而是在精度、带宽、稳定性与生态延展性之间取得务实平衡。选择,从来不是挑选最强的一张卡,而是找到与你当下课题节奏共振的那一块硅基引擎。



































































































评论
更多评论