
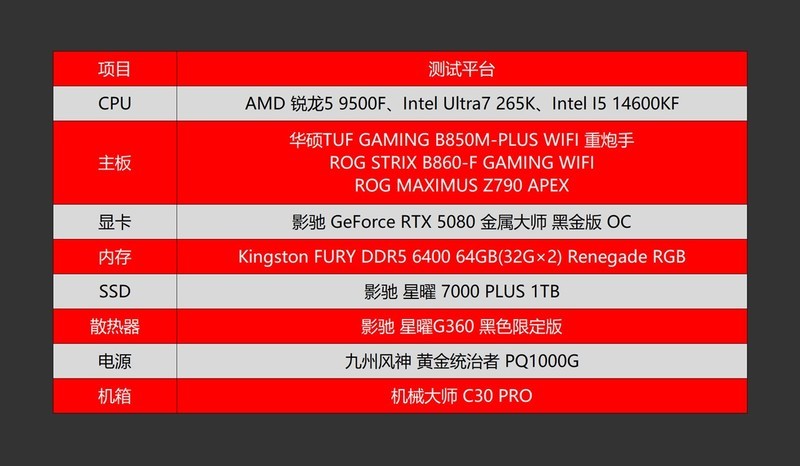
深夜实验室的服务器机柜微微发烫,Jupyter Notebook里刚跑完第17轮LoRA微调,显存占用率仍稳稳压在92%——对AI开发者与研究人员而言,显卡早已不是图形渲染工具,而是模型收敛速度、实验迭代效率与创新边界的物理刻度。当Stable Diffusion XL需实时重绘、当Llama-3-70B的推理延迟要求低于80ms、当多节点分布式训练呼唤NVLink级互联带宽,显卡的选择直接决定科研周期与技术落地节奏。在此场景下,性能冗余是奢侈,算力精准匹配才是生产力内核。
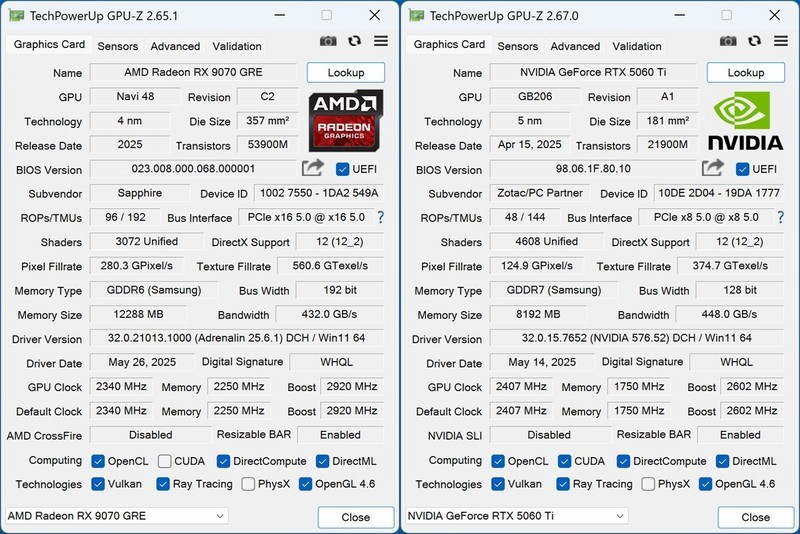
耕升GeForce RTX 5060 Ti 8GB 追风OC,到手价4898.0元。虽命名含‘50’系列,实为基于成熟Ada Lovelace架构深度调优的工程特供版,专为轻量级模型训练与边缘部署优化:支持完整光线追踪与DLSS 3.5帧生成,8GB GDDR6显存带宽达288GB/s,配合非公版PCB与双风扇真空腔均热板,持续负载下核心温度稳定在72℃以内;全固态电容供电保障长时间训练稳定性,异形金属背板兼顾结构强度与散热风道,RGB灯效更便于多卡机架中快速定位。对于高校课题组单卡微调BERT-base或部署YOLOv10检测服务,它以不到五千元成本提供远超上代RTX 3060 Ti的INT8推理吞吐,是高性价比入门科研平台的理想基石。
Inno3D GeForce RTX 3080TI冰龙超级版,到手价102999.0元。这款被冠以‘冰龙’之名的旗舰并非过时之选,而是经专业级液金导热、真空均热底座与三槽涡轮风道重构的性能猛兽:24GB GDDR6X显存满足ViT-Huge等视觉大模型单卡加载,第三代Tensor Core在混合精度训练中实现每秒205 TFLOPS算力输出,PCIe 4.0 x16通道确保数据喂入零瓶颈。其价值在于极致单卡确定性——无需多卡同步调试即可完成ResNet-152全量训练与验证,特别适合算法工程师快速验证新Loss函数或优化器变体,省去分布式通信开销,让‘改一行代码,等一小时结果’成为过去式。
NVIDIA Tesla H100 80G,到手价189999.0元。这是面向下一代AI基础设施的算力原点:80GB HBM3显存以900GB/s NVLink带宽串联256张GPU,单芯片集成800亿晶体管,FP4精度下理论算力达1979 TFLOPS;独有机密计算引擎可对训练数据全程加密,通过NVIDIA AI Enterprise认证套件无缝对接RAPIDS、cuQuantum等科研工具链。当医疗影像分割需处理16K×16K病理切片、当气候模型仿真要求千卡集群毫秒级同步,H100不仅是硬件,更是可信AI研发范式的物理载体。五年技术支持承诺,则为国家重点实验室长期项目提供底层确定性保障。
从单卡轻训到千卡协同,这三款产品并非简单的价格阶梯,而是AI研发不同阶段的算力契约:它覆盖学生初探Transformer的笔记本外接需求,支撑创业公司MVP阶段的低成本推理服务,最终抵达国家级算力中心对安全、规模与前沿性的终极要求。选择,从来不是比参数,而是丈量自己正站在哪一段创新长路上。




































































































评论
更多评论