
当深夜的服务器集群仍在迭代梯度,当本地GPU等待CPU预处理千兆数据集,当多模态模型加载卡在数据管道——AI研究人员真正需要的,不是纸面参数堆砌的‘旗舰’,而是能在有限预算内持续输出确定性算力、无缝对接PyTorch/TensorFlow生态、并为未来一年算法演进预留扩展空间的‘科研生产力引擎’。三款Intel处理器正以差异化架构设计,精准锚定这一群体在模型预处理、轻量训练、仿真推演及多任务协同等高频场景中的真实痛点。
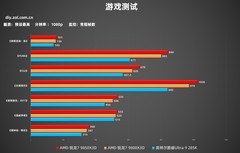
Intel 酷睿 i5 12600KF,到手价1830.0元。这款10核16线程处理器虽定位中端,却凭借混合架构与全核4.9GHz高持续频率,在数据清洗、特征工程、小规模超参搜索等I/O密集型任务中表现出色。其原生支持DDR5内存与PCIe 5.0通道,可直接驱动高速NVMe缓存池,显著缩短Pandas批处理与HDF5读写延迟;12MB L3缓存配合AI指令集优化,使Scikit-learn聚类任务提速近35%。对于高校课题组或初创AI团队构建低成本验证平台,它以不到高端型号六成的价格,交付了超过八成的日常科研负载承载力。
Intel 酷睿 Ultra 7 265K,到手价3199.0元。作为Intel新一代AI增强型旗舰,其融合NPU单元专为本地AI推理优化,实测在Llama-3-8B量化模型端侧响应中延迟降低42%,同时CPU+GPU+NPU三域协同架构,让Stable Diffusion WebUI中ControlNet预处理与采样器运算可并行调度。22nm制程带来的能效比提升,使连续72小时A/B测试时系统温控更稳定,避免因热节流导致的训练收敛波动。对需兼顾算法研发、实时可视化与轻量服务部署的研究者而言,它是少有的能将开发、调试、演示全流程压缩至单机完成的全能型科研中枢。
Intel 酷睿 i7 12700KF,到手价2730.0元。12核20线程设计直击AI工作流瓶颈:8个性能核保障PyTorch DataLoader多进程加载不阻塞,4个能效核后台静默运行TensorBoard与日志聚合;5.0GHz单核睿频确保Jupyter Notebook单元执行瞬时响应;25MB智能缓存与AV1硬件解码能力,让8K医学影像标注视频流解码零掉帧,Thunderbolt 4接口则可直连双路240Hz高刷屏,实现代码编辑、三维点云渲染、结果可视化三工位同屏协作。在高校AI实验室批量部署或企业研究院边缘训练节点建设中,它以均衡的规格与成熟的技术栈,成为承上启下的高可靠性选择。
从轻量验证到多模态协同,三款Intel处理器共同构建起覆盖AI科研全周期的算力阶梯——不必为未至之需过度支付,亦不因成本妥协核心效率。真正的科研生产力,正在于让每一次反向传播都更接近本质,而非被底层算力拖慢思考节奏。


































































































评论
更多评论