
当深夜实验室的服务器风扇仍在低鸣,当Jupyter Notebook里新一轮LoRA微调刚刚启动,当数据集加载卡在第7个batch——AI开发者真正需要的,不是参数堆砌的纸面性能,而是稳定、精准、可持续释放算力的图形计算单元。面对模型参数量持续攀升、多模态预处理流程日益复杂、本地部署需求快速落地的现实挑战,显卡已从单纯的游戏硬件演变为AI研发链路中不可替代的算力基石。它既要扛得住Stable Diffusion XL的图生图迭代,也要稳得起Llama-3-8B的量化推理,更需在连续72小时训练中保持温度与功耗的理性边界。
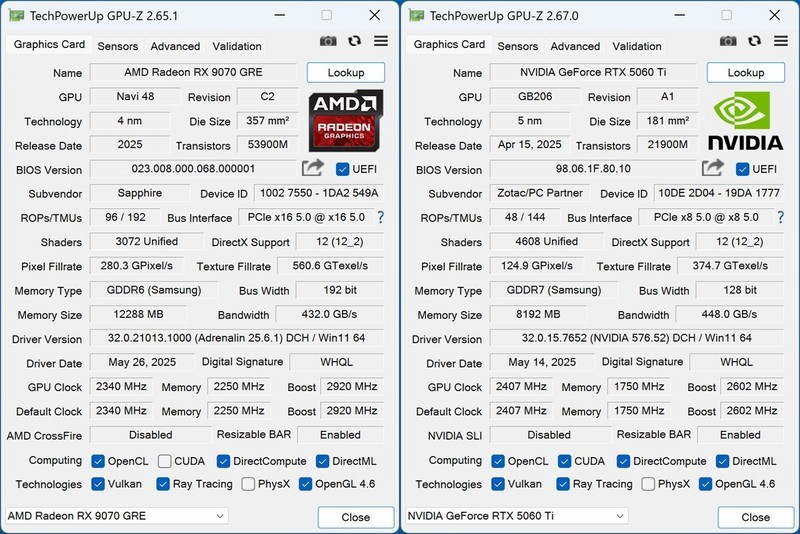
NVIDIA Tesla A10 24G,到手价21999.0元,是面向严肃科研场景的专业级选择。其基于Ampere架构,专为数据中心与AI推理优化设计,支持Tensor Core加速与NVLink互联扩展,FP16算力达31.2 TFLOPS,24GB ECC显存保障大规模张量运算容错能力。对于高校实验室开展自然语言理解联合建模、医疗影像分割模型训练等对稳定性与精度要求极高的项目,A10凭借成熟驱动生态、完整CUDA工具链支持及长期运维可靠性,成为值得信赖的底层支撑。
微星GeForce RTX 4060 Ti VENTUS 3X 16G OC,到手价2699.0元,以极致性价比切入个人开发者与初创团队场景。虽定位主流级,但搭载Ada Lovelace架构与第三代RT Core,在INT4/FP8稀疏计算支持下,可高效运行Qwen-1.5-4B等中等规模模型的本地推理与轻量微调;16GB GDDR6显存足以承载SDXL LoRA多任务并发,三风扇散热系统确保长时间编译与调试过程中的静音与低温表现,是学生研究者、独立AI应用开发者构建低成本实验平台的理想起点。
微星Radeon RX 7900 XTX GAMING TRIO CLASSIC 24G,到手价8999.0元,代表AMD在AI开发生态中的强势回归。24GB超大显存配合520GB/s显存带宽,显著提升ViT类视觉大模型的数据吞吐效率;支持ROCm 6.0框架,已实现PyTorch 2.3+原生适配,在图像生成、视频理解等RDNA3架构优势领域展现出优异能效比;Triple BIOS设计兼顾静音模式与性能压榨,配合微星TRI FROZR散热系统,满足本地多卡微调与实时AIGC服务部署的双重诉求。
三款产品覆盖从入门验证、中试迭代到规模化部署的完整AI研发周期:A10筑牢科研底座,4060 Ti激活个体创造力,7900 XTX拓展国产化算力新路径。无论身处高校实验室、科技企业研究院,还是自主创业的技术工作室,理性匹配任务负载与预算约束的GPU选型,才是加速智能时代落地的第一步。





































































































评论
更多评论