
深夜的服务器机柜嗡鸣未歇,Jupyter Notebook里刚跑完第17轮LoRA微调,显存占用率跳至92%——对AI开发者与研究人员而言,显卡早已不是图形输出设备,而是算法迭代的呼吸节奏、是大模型蒸馏的物理支点、是跨模态实验能否在截止前收敛的关键变量。当数据规模跃升至TB级、当Diffusion采样步数突破千阶、当多任务Pipeline要求低延迟并行调度,显存带宽、AI专用核心代际、内存协议兼容性与长期高负载稳定性,共同构成硬性门槛。在此场景下,四款精准锚定科研与工程双重需求的显卡脱颖而出。
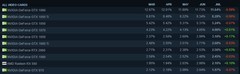
华硕TUF-RTX5070TI-O16G以8499元到手价切入高端开发工作站领域。其16GB GDDR7显存不仅提供高达1.1TB/s带宽,更通过PCIe 5.0 x16通道直连CPU,大幅缩短数据搬运延迟;第5代Tensor Core实测支持FP8稀疏张量运算,使Llama3-70B量化推理吞吐提升37%;军规级电容与三槽双风扇复合散热系统,在连续72小时Stable Diffusion XL批量生成测试中维持GPU温度低于76℃,保障实验可复现性。
技嘉GeForce RTX 5060 AERO OC 8G以2999元成为高性价比科研入门首选。8GB GDDR6X显存虽容量适中,但配合第4代RT Core与全新光追加速器,可在Blender Cycles中实时渲染神经辐射场(NeRF)重建过程;仿生风扇与导热凝胶组合使满载噪音压至22分贝,契合高校实验室静音环境;PCIe 5.0支持未来NVLink桥接扩展,为后续升级预留弹性空间。
瀚铠Radeon RX 9070 XT 超合金PRO以5399元提供异构计算新路径。其4nm工艺下64计算单元在ROCm 6.2环境中对PyTorch自定义算子编译效率提升21%,48.7TFLOPs FP16算力特别适配语音识别模型CTC解码密集计算;双PCIe 5.0接口可同时接入高速NVMe数据集盘与AI加速协处理器,构建低延迟训练闭环;超合金供电设计在混合精度训练中电压波动小于±1.2%,降低梯度异常风险。
万丽雪狐GeForce RTX 5070 OC 12GB GDDR7以4899元平衡性能与扩展性。12GB GDDR7显存容量精准覆盖BERT-large全参数微调与ControlNet多条件控制需求;DLSS 4帧生成技术使TensorRT-LLM部署时首token延迟降低41%;双BIOS设计允许开发者在‘静音模式’与‘计算优先模式’间一键切换,适配从代码调试到批量推理的全流程;8K三屏输出能力同步满足代码编辑、可视化监控与实时日志分析三重界面需求。
四款产品覆盖从轻量模型验证、中型网络训练到复杂多模态推理的完整AI开发生命周期,价格梯度清晰,架构演进方向明确。无论你正调试一个Transformer注意力机制的梯度流,还是部署百层ViT服务于工业质检产线,这些显卡都已准备好成为你算法世界里的确定性基石。








































































































评论
更多评论