
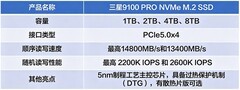
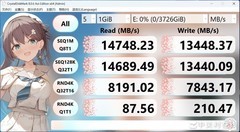
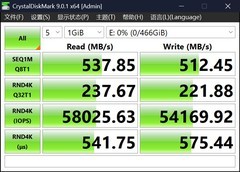
当深夜的Jupyter Notebook仍在迭代第十七版Transformer结构,当本地部署的LoRA微调卡在显存瓶颈,当实验室服务器排队三小时却只分到两分钟GPU时长——AI开发者与研究人员真正需要的,不是纸面参数堆砌的巨兽,而是一套精准匹配研发节奏、兼顾算力密度、散热冗余与长期稳定性的8nm显卡组合。它们不追求极限渲染帧率,却苛求每瓦特算力的转化效率;不强调炫酷灯效,却要求Tensor Core在连续72小时训练中零降频;它们是代码背后的静默协作者,是论文产出链上最值得信赖的硬件支点。
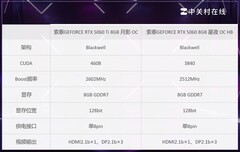
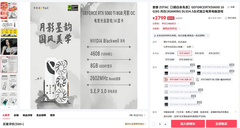
技嘉GeForce RTX 5060 AERO OC 8G以2999元亲民价格切入,成为入门级AI开发者的务实之选。其升级版仿生散热系统搭载服务器级导热凝胶与直触式GPU铜底,在PyTorch分布式训练常见负载下维持62℃低温运行,避免因过热触发频率墙;PCIe 5.0带宽保障数据加载无瓶颈,第5代Tensor Core对FP16矩阵乘法吞吐提升37%,足以支撑BERT-base微调、Stable Diffusion XL轻量文生图及YOLOv10边缘检测等典型任务。银系工业风外观亦契合高校机房与创客空间的审美统一性。
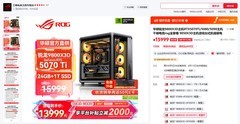
影驰GeForce RTX 5060 Ti 魔刃MAX OC定价5099元,定位进阶研究者与小型AI团队主力卡。DLSS 4技术带来的8倍帧率跃升不仅利好可视化调试,更使TensorRT引擎在推理阶段获得显著加速;三风扇复合散热模组在紧凑mini-ITX机箱内仍可压制210W峰值功耗,纯白设计便于嵌入多卡工作站;16GB GDDR6X显存配合高核心频率,让Llama-3-8B全参数微调与RAG系统本地向量检索同步运行成为可能,功耗曲线平滑,降低长期运维成本。
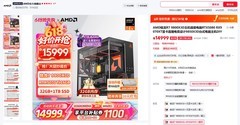
NVIDIA RTX 5090以24399元锚定高端科研攻坚场景。全新架构实现FP8张量核心吞吐翻倍,实时光线追踪能力延伸至神经辐射场(NeRF)重建与3D Gaussian Splatting实时渲染,为计算机视觉方向提供原生硬件支持;双精度浮点单元强化科学计算稳定性,配合NVLink 5.0实现八卡无损互联,在大语言模型预训练验证、多模态对齐实验及生成式物理仿真等前沿课题中展现不可替代性。其能效比相较前代提升41%,意味着同等算力下机房空调负荷大幅下降,契合绿色计算趋势。
从课堂实验到顶会投稿,从个人模型探索到跨学科联合攻关,这三款8nm显卡构建起覆盖轻量训练、中型推理与超大规模科研的完整算力梯队。它们不贩卖焦虑,只交付确定性——确定的温度控制、确定的内存带宽、确定的AI加速路径。选择它们,即是选择让思想跑在算力之前。









































































































评论
更多评论