
2026年2月13日,国内人工智能领域迎来一次集中发布:智谱GLM-5、Minimax 2.5以及DeepSeek三款大模型于同日推出新版。其中,DeepSeek此次更新引发广泛关注。
本次迭代的核心升级在于上下文长度,由上一代V3系列的128K大幅扩展至100万tokens,相当于提升约七倍。DeepSeek已于当晚在其官方社群中正式确认该进展,并指出网页端与移动应用端已启动新长文本模型架构的测试,全面支持100万tokens上下文处理能力。
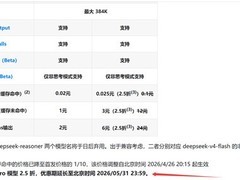
需注意的是,当前API服务仍沿用V3.2版本模型,上下文窗口维持在128K不变。据官方说明,此次发布的新模型仍为纯文本模型,主要优化方向集中于上下文承载能力——这一改进对多轮深度对话、复杂文档理解及长程逻辑推理等场景具有显著意义。
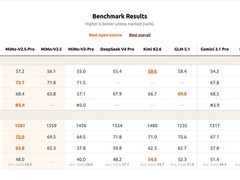
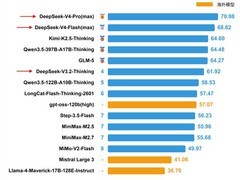
部分用户实测反馈显示,新模型在代码生成质量、响应效率等方面亦有可观提升。但相较此前市场预期,本次更新在整体能力跃迁层面略显保守。技术参数层面,该模型参数量约为2000亿,明显低于V3系列的6700亿,部分任务表现甚至略逊于前代。由此推测,该版本更可能定位为V4系列的轻量先行版,即V4 Lite。
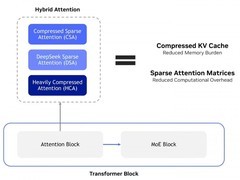
DeepSeek未来规划中的完整版V4,据传将采用约1.5万亿参数规模,较V3实现翻倍以上增长;同时整合此前自研的Engram与mHC等核心技术路径,在性能增强的同时兼顾推理成本控制。该版本的技术定位与应用潜力,目前仍被业界普遍寄予较高期待。






























































评论
更多评论