
2026年6月4日,英伟达在台北举行的全球技术大会上正式推出Cosmos 3模型,并将其定义为全球首个完全开源、具备全场景适应能力的通用智能模型。
该模型专为机器人系统、自动驾驶车辆及视觉智能体研发,核心能力聚焦于视觉驱动的深度推理,同时支持文本、图像、视频、环境声音及动作序列等多模态内容的协同生成。
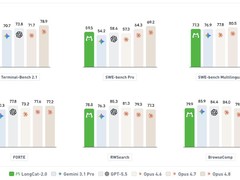
Cosmos 3采用双Transformer模块架构:推理Transformer专注于解析物体间的交互逻辑、运动路径以及时空动态关系;生成Transformer则基于上述理解,精准输出视频帧与动作轨迹。这种分阶段建模方式使系统能够首先构建对物理世界的内在认知,再据此生成符合现实规律的画面与行为响应,从而显著增强对真实复杂环境的表征与推演能力。
长期以来,机器人与视觉智能体在真实物理场景中的感知与决策能力受限于高质量训练数据匮乏、仿真平台割裂等问题,导致其对世界运行规律的学习效率偏低。Cosmos 3旨在突破这一瓶颈,以更高精度的物理建模为基础,原生支持多模态信息的理解与生成,推动智能体从感知走向具身认知。
在功能定位上,Cosmos 3既可作为视觉语言模型执行跨模态理解任务,亦可承担世界模型角色,用于模拟物理环境演化并预测未来状态;同时,它也设计为开放架构,可作为其他世界模型研发的底层支撑平台。
产品序列方面,面向高精度计算场景的Cosmos 3 Super与适用于资源受限设备的Cosmos 3 Nano已同步发布并投入实际应用;专为边缘端实时推理优化的Cosmos 3 Edge版本将在后续阶段推出。
技术实现上,模型依托Transformer结构——一种擅长捕捉长距离上下文依赖关系的神经网络范式,通过高度并行化的计算机制提升处理效率。此次将推理与生成能力深度耦合,标志着英伟达在构建面向具身智能的物理世界基础模型方面迈出关键一步。





































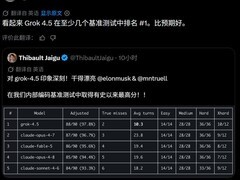











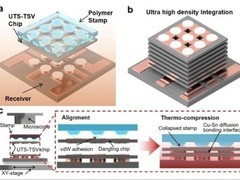












评论
更多评论