
深夜调试模型时显存带宽突然成为瓶颈,数据加载拖慢训练节奏;多任务并行推理中显存位宽不足导致显存复用效率骤降;在本地部署轻量化大模型或3D神经辐射场重建时,256bit显存位宽带来的192GB/s以上带宽优势,正悄然决定着实验迭代速度与工程落地可行性。对AI开发者与研究人员而言,显卡不仅是图形加速器,更是算法验证、模型压缩、特征可视化与跨模态合成的核心计算单元——它需要稳定、可预测的内存带宽,扎实的FP16/INT8算力支撑,以及长期高负载下的可靠性表现。
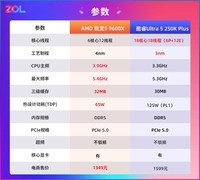
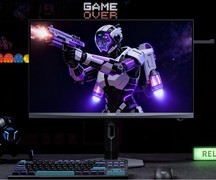
NVIDIA RTX A2000显卡以3360.0元的亲民价格切入专业领域,搭载256bit显存位宽与6GB GDDR6显存,提供高达192GB/s的显存带宽。其基于Ampere架构的48个第三代Tensor Core与16GB/s的PCIe 4.0接口,使其在轻量级模型微调、边缘AI部署及Jupyter交互式开发中表现出色。低功耗设计(70W TDP)更适配多卡嵌入式工作站或高校实验室机柜空间受限环境,是注重能效比与长期稳定性的研究团队理想起点。
华硕DUAL-RTX4070-12G以4799.0元提供当前消费级专业显卡中的均衡旗舰体验。256bit位宽匹配12GB GDDR6X显存,带宽跃升至504GB/s,配合DLSS 3.5与第四代Tensor Core,在Stable Diffusion XL本地推理、NeRF实时重建、3DGS训练等新兴AI视觉任务中响应迅捷。双风扇静音散热与金属背板设计保障7×24小时持续运行稳定性,特别适合需兼顾教学演示、模型服务API部署与中小型数据集训练的实验室场景。
七彩虹iGame GeForce RTX 3060 Advanced OC 12G定价3699.0元,虽属上一代架构,却凭借256bit位宽与12GB大容量显存,在CV/NLP混合任务中展现出惊人适应性。其OC超频版强化供电与真空腔均热板散热,显著提升长时间训练下的频率维持能力;CUDA核心达3584个,对PyTorch分布式DataLoader吞吐优化友好,是预算有限但需承载BERT-base微调、YOLOv8多尺度训练及TensorBoard可视化等复合负载的研究生与初创AI团队高性价比之选。
三款产品均锚定256bit显存位宽这一关键性能基线,在显存带宽、容量与功耗间取得差异化平衡:RTX A2000胜在专业认证与能效,RTX 4070强于前沿AI特性与综合吞吐,RTX 3060则以成熟生态与成本控制满足务实型科研需求。无论你是构建个人AI实验台,升级课题组计算节点,还是为课程设计搭建可扩展训练平台,这张256bit显存显卡推荐榜都提供了经场景验证的可靠选项。





































































































评论
更多评论