
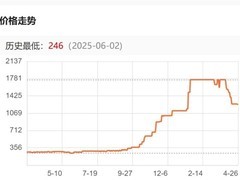
四月二十六日深夜,DeepSeek正式推出全系列API服务价格调整方案,其中针对输入缓存命中的计费标准大幅下调至原价的十分之一。
调整后,DeepSeek-V4-Pro模型在缓存命中场景下,每百万tokens输入费用为零点一元;叠加此前于四月二十五日启动的限时二点五折优惠,实际价格进一步降至每百万tokens零点零二五元。DeepSeek-V4-Flash模型在相同条件下,每百万tokens输入费用为零点零二元。
此次折扣活动将持续至二零二六年五月五日二十三时五十九分(北京时间)。
此外,DeepSeek同步宣布,原有模型名称deepseek-chat与deepseek-reasoner将逐步停止使用。为保障用户平滑过渡,二者功能已分别整合进DeepSeek-V4-Flash模型:前者对应该模型的非推理模式,后者对应其推理模式。


























































评论
更多评论