
近日,有技术资讯披露,根据一项最新公布的专利内容,AMD 正在研究采用“智能开关”技术以优化数据处理流程,旨在缓解多芯粒 GPU 所面临的延迟问题。
消息称,AMD 在消费级 GPU 领域正酝酿新的布局,计划在未来产品中引入多芯粒模块(Multi-Chiplet Module,MCM)架构。这种设计方式虽非首次亮相,但其在高性能计算领域的应用前景引发了广泛关注。
实际上,AMD 在多芯粒技术方面已有一定积累,例如在其 Instinct MI200 系列 AI 加速器中,就采用了在同一封装中堆叠多个图形处理核心、高带宽内存以及 I/O 控制模块的设计方案。
然而,将多芯粒结构应用于游戏类 GPU 仍面临诸多挑战。其中最大的难题在于,图形渲染过程中对数据访问的实时性要求极高,而芯粒间的远程通信往往会造成明显延迟,影响整体性能发挥。
为了解决这一瓶颈,AMD 在新专利中提出了一种名为“数据链路电路与智能开关”的技术方案。该方案的核心在于通过智能开关来提升计算单元与内存控制器之间的通信效率。
从本质上讲,这种“智能开关”可以看作是 AMD Infinity Fabric 技术的一种轻量化延伸。考虑到消费级 GPU 的成本与制造工艺限制,该设计并未采用 HBM 内存芯粒,而是通过极低延迟的切换机制(响应时间仅数纳秒)实现更高效的内存访问路径。
在优化通信路径的基础上,专利还建议在每个图形计算核心(GCD)中集成 L1 和 L2 缓存,类似于当前 AI 加速器所采用的方式。此外,所有 GCD 还能通过智能开关访问一个共享的 L3 缓存或堆叠式 SRAM 模块,从而构建起一个统一的数据共享平台,有效降低对外部全局内存的依赖,同时提升芯粒间数据交换的效率。















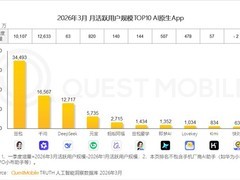





















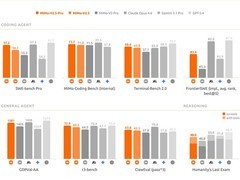


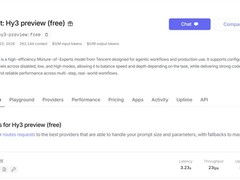
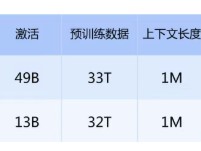


























评论
更多评论