
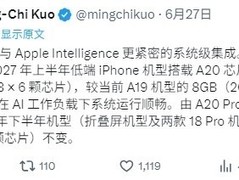
小米人工智能实验室于2026年6月4日正式开源可控视频音效生成模型ControlFoley。该模型能够依据视频画面内容,智能生成高度贴合的环境音效与背景音乐,并支持用户通过自然语言指令,精准调节音效的风格、强度、节奏等维度,标志着视频内容生产环节中音效自动化技术取得重要进展。
ControlFoley采用扩散模型架构,在逾百万组高质量视频-音频配对数据上完成训练。模型具备细粒度视觉理解能力,可识别画面中的动作行为、空间场景及物体属性,并据此生成匹配的音效,例如脚步声、风声、物体碰撞声等。
该模型的核心突破在于实现高精度可控生成:用户仅需输入简明文本提示,如“轻柔的雨声”或“紧张的鼓点”,系统即可按需调整输出结果。模型同时支持单条视频处理与多视频批量生成,单条视频音效生成耗时稳定在三至五秒之间。
在技术指标方面,ControlFoley支持48kHz高采样率音频输出,生成音质达到专业制作水准。开源内容涵盖预训练权重、完整推理代码及详尽使用文档,便于开发者快速集成与二次开发。
该模型适用于短视频内容创作、游戏音效设计、影视后期辅助等多个领域。对于个体创作者而言,它显著降低了音效制作的专业门槛与时间成本。研发团队表示,未来将视实际需求与反馈,探索面向终端用户的在线服务形态。

























































评论
更多评论