
2026年4月25日,DeepSeek-V4大模型正式开源。华为AI数据平台同步完成深度适配,此次适配并非简单的模型兼容,而是覆盖存储、算力与推理全流程的系统性协同升级,显著提升了长文本大模型的实际运行效率。
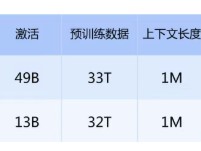
DeepSeek-V4的核心突破在于将上下文窗口扩展至100万Tokens,可高效处理超长文档及多轮复杂对话任务。然而,如此规模的上下文能力对底层硬件提出严峻挑战:数据读写模式更趋碎片化,缓存加载速度要求大幅提升,传统架构常面临响应迟缓、部署困难等问题。
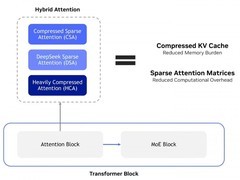
华为并未止步于基础对接,而是通过自研核心组件UCM推理记忆数据管理,直击关键瓶颈。该组件采用智能IO聚合技术,将大量零散随机读写操作整合为高吞吐的连续数据传输,有效缓解硬件负载压力;同时引入PMR-TREE智能后缀联想机制,在论文摘要生成、内容结构化提取等典型场景中,推理效率提升超过30%。
依托OceanStor A系列AI存储系统,平台进一步实现存算深度融合——数据无需反复搬运,可直接供给计算单元,大幅缩短处理路径,加快整体响应速度。
此次深度适配标志着大模型技术已跨越实验室验证阶段,迈入稳定、可靠、可规模部署的生产应用新阶段。依托全栈自主技术能力,华为为百万级上下文大模型构建起坚实底座,也推动国产大模型与国产算力之间的协同更加紧密、高效与成熟。


































































评论
更多评论