
2026年4月24日,DeepSeek正式发布V4预览版并同步开源,该模型具备百万级字符的超长上下文处理能力。
摩尔线程联合智源众智及FlagOS社区宣布,已在旗舰级AI训推一体GPU——MTT S5000上完成DeepSeek-V4-Flash大模型的首日极速适配,全面支持全量核心算子的深度优化与部署。
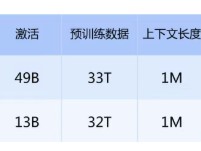
DeepSeek-V4-Flash采用混合专家(MoE)架构,总参数量达2840亿,每次推理激活参数约130亿,支持百万Token上下文长度,并首次引入FP4与FP8混合精度计算方案,对底层算力硬件提出更高标准。
摩尔线程MTT S5000是国内首款原生支持FP8计算的全功能GPU,内置硬件级FP8 Tensor Core。相较传统BF16或FP16精度,该设计可使显存带宽压力降低50%,同时实现计算吞吐量翻倍提升。
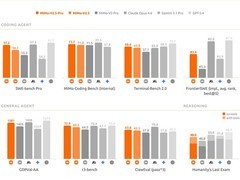
本次适配由智源FlagOS团队主导完成FP8量化工作,重点聚焦FP8核心算子与稀疏注意力(Sparse Attention)算子两大技术方向,取得关键进展:一方面依托FlagTree编译器实现精细化张量形状对齐与矩阵运算加速;另一方面通过FlagOS-Tune自动搜索最优内核配置,性能显著优于人工调优。实测数据显示,启用自动调优后,首词生成时延(TTFT)下降16.5%,逐词生成时延(ITL)下降39.7%,整体吞吐量提升65.7%。
目前,DeepSeek-V4-Flash已在MTT S5000平台完成全面适配;更大规模的DeepSeek-V4-Pro版本(参数量1.6万亿)亦正加速推进迁移与适配工作。
开发者可通过魔塔平台及HuggingFace获取预置镜像,即刻部署使用。




























































评论
更多评论