
2026年4月24日,小米正式推出MiMo-V2.5语音模型系列,涵盖MiMo-V2.5-TTS语音合成与MiMo-V2.5-ASR语音识别两大核心模块。该系列专为智能体时代构建,实现语音输入与输出的全链路覆盖,使语音交互可如语言本身一般被灵活调用与编排。
在语音合成方向,MiMo-V2.5-TTS系列提供三款差异化模型,适配多元创作需求:
第一款为标准版MiMo-V2.5-TTS,集成多套经专业打磨的高品质音色,发音自然流畅,情感表达准确贴切。支持对语速、情绪强度、语气倾向等维度进行细粒度调节,开箱即可投入实际应用,兼顾效率与表现力。
第二款为MiMo-V2.5-TTS-VoiceDesign,具备基于文本生成全新音色的能力。用户仅需用自然语言描述目标声音特征,例如“语速舒缓、略带鼻音的中年教师”或“语调轻快、富有跳跃感的青少年主播”,模型即可自主生成匹配的声音形象。该能力突破传统性别、年龄等粗略分类限制,可理解并响应涉及口音、音质质感、性格气质乃至模糊甚至存在张力的复合型描述,依托大规模预训练所形成的语义泛化能力,实现高保真声音构想。
第三款为MiMo-V2.5-TTS-VoiceClone,专注高保真音色复刻。用户只需提供数秒原始音频,无需训练、无需微调,即可精准还原播客主理人、专业配音演员、品牌代言人乃至用户本人的声音特质。复刻结果不仅保留音色本体,更完整继承呼吸节奏、语流停顿、重音习惯等个性化韵律特征。在此基础上,还可叠加自然语言指令、音频标记或结构化脚本,进一步拓展语音内容的创作深度与表达自由度。
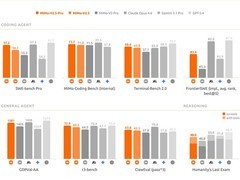
作为整套语音模型体系的感知基础,MiMo-V2.5-ASR在语音识别层面展现出全面的场景适应性:在中英文混合、中文多方言、语码转换、强背景噪声、多人交替说话以及高信息密度对话等真实复杂环境中,均达到当前行业领先水平。
目前,MiMo-V2.5-TTS、MiMo-V2.5-TTS-VoiceDesign与MiMo-V2.5-TTS-VoiceClone三款模型已同步上线Xiaomi MiMo API开放平台,并面向开发者限时免费开放调用。































































评论
更多评论