
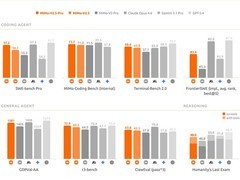
2026年4月21日,一项针对RAG(检索增强生成)人工智能工作负载的实测结果显示,搭载3D V-Cache技术的AMD处理器在多项关键指标上显著优于同代非X3D架构产品,最高性能优势达88%。
RAG技术通过调用外部向量数据库来提升大语言模型输出的准确性与相关性。与传统纯大模型推理不同,该流程中向量检索环节的计算压力主要集中于CPU,而非GPU。随着以智能体为核心的AI应用逐步普及,依赖实时检索的任务比重持续上升,CPU在低延迟响应方面的表现已成为系统整体效率的关键制约因素。以HNSW(分层可导航小世界)算法为代表的图结构检索方法,正是典型代表——其执行过程需在GPU运行大模型推理的同时,由CPU高效完成图遍历与近邻搜索,此时更大的片上缓存容量可有效减少数据访问延迟,从而加速整个RAG流水线。
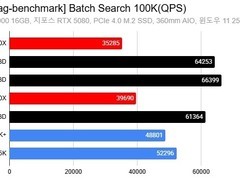
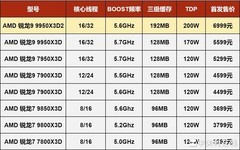
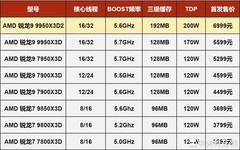
本次测试基于开源X3D RAG基准工具,聚焦个人电脑及小型团队单节点部署场景,测试规模覆盖约10万至20万向量的数据集,对比对象包括AMD锐龙9000X3D系列处理器及多款同代非X3D型号。
实测数据显示:在10万向量批量检索任务中,X3D处理器相较非X3D型号最快提升达88%;在20万向量规模下,同为8核心的锐龙7 9850X3D比锐龙7 9700X提速逾50%,且其检索速度甚至超越16核心的锐龙9 9950X。索引构建效率方面,X3D处理器在10万向量任务中耗时缩短一半,在20万向量任务中减少39%。并发RAG请求处理能力同样由X3D平台保持领先。
唯一差距相对有限的指标为首Token生成时间(TTFT),因其主要瓶颈在于GPU侧的模型推理速度,CPU影响权重较低。





























































评论
更多评论