
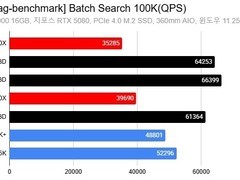
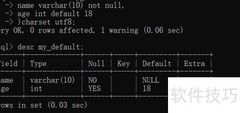
在实际测试中,AMD X3D架构处理器在检索增强生成类人工智能任务中展现出显著性能优势,其表现远超预期。在RAG基准测试中,X3D处理器最高较同代非X3D型号提升达88%。
RAG技术通过调用外部向量数据库补充信息,从而提升大语言模型输出的准确性与相关性。与传统纯LLM推理不同,该流程中向量检索环节主要由CPU承担,计算压力集中于内存访问延迟、缓存效率及数据吞吐能力。
随着智能体驱动型AI应用不断普及,以搜索为核心的任务流比例持续上升,CPU在响应延迟方面的制约日益成为系统性能的关键瓶颈。以HNSW图索引搜索算法为例,在GPU执行模型推理的同时,CPU需实时完成高并发图结构遍历。此时,更大容量、更低延迟的片上缓存可大幅压缩单次检索耗时。
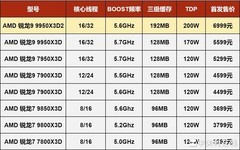
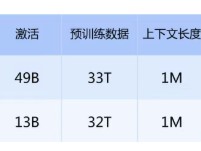
本次测试基于开源X3D RAG基准框架,面向个人工作站及小型团队单节点部署场景,设定向量规模为10万至20万条。参测产品涵盖AMD锐龙9000系列X3D型号及多款主流非X3D处理器。
实测数据显示:在10万向量批量检索任务中,X3D处理器最快实现88%的性能领先;在20万向量测试中,8核锐龙7 9850X3D相较同为8核的锐龙7 9700X提速逾50%,且其检索速度已超越16核的锐龙9 9950X。
在索引构建阶段,X3D处理器同样表现突出:10万向量建索引时间缩短50%,20万向量建索引时间缩短39%。并发RAG请求处理能力亦由X3D型号保持领先。
仅在首Token生成时间(TTFT)相关指标上,X3D处理器优势不明显,因该环节主要受GPU算力与模型加载效率影响,对CPU依赖程度较低。



























































评论
更多评论