
深度求索(DeepSeek)计划于未来数周内发布其新一代旗舰级人工智能模型,代号V4,预计发布时间在2月中旬,临近农历新年。据知情人士透露,该模型将聚焦于代码生成能力的全面提升,在处理超长代码提示方面取得关键进展,支持高达百万级token的上下文窗口,能够一次性解析中型规模的完整代码库、技术文档及需求说明,精准识别跨文件的依赖关系,有效缓解复杂软件开发中的上下文断裂问题。这一能力对于大型系统构建、遗留代码重构以及复杂技术资料的理解具有显著意义。
V4在训练机制上亦实现重要突破,解决了传统模型在持续训练过程中理解能力逐渐下降的问题,实现了数据模式理解在整个训练周期内的稳定性。这使得模型不再局限于对训练数据的简单记忆,而是能够更高效地从大规模数据中提取抽象规律,形成更深层次的认知能力。
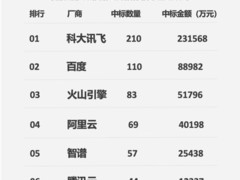
根据公司内部基准测试结果,V4在代码生成任务中的表现已超越当前主流同类模型,包括Anthropic的Claude系列及生成式预训练变换器系列等。此外,有行业信息指出,V4或采用全新的mHC架构,具备更强的并行计算效率和对国产芯片的良好适配性,有望在部署成本和推理速度方面带来优化,为后续大规模商业化应用提供支撑。
值得关注的是,本月4日,DeepSeek在arXiv平台更新了其R1模型的研究论文,篇幅由原22页扩展至86页,新增内容涵盖完整的训练流程解析及超过20项评测基准的详细数据,被视为为V4正式发布所做的关键技术铺垫。


































































评论
更多评论