
当业界普遍聚焦于模型智能水平的比拼时,DeepSeek持续关注更具实际价值的挑战:如何显著提升大语言模型的推理速度。
二零二六年六月二十八日,DeepSeek在开源平台正式发布其全新推理加速框架DSpark,并同步公开相关论文。该框架旨在突破高并发场景下大语言模型推理效率的关键瓶颈。
本研究由DeepSeek与北京大学联合完成,DeepSeek创始人梁文锋参与其中并列名作者。项目开源了DSpark的全部模型权重,并配套发布面向推测解码的算法训练代码库DeepSpec。
论文首先指出当前大语言模型的核心制约因素:其自回归生成机制要求每生成一个新词元,都必须基于全部已生成词元执行一次完整前向计算。随着输出长度增加,延迟呈非线性上升,导致GPU资源利用率偏低,用户响应时间延长。这一问题在实时对话助手、多轮智能体协作等对延迟高度敏感的服务场景中尤为突出。
目前主流优化路径主要有两类:一类依托自回归结构的草稿模型,另一类采用并行架构的草稿模型。二者虽各有尝试,但在生成质量与系统效率之间难以兼顾,且普遍缺乏对运行负载动态变化的适应能力。
针对上述局限,DeepSeek提出DSpark推测解码框架,采用半自回归生成架构——既保留并行主干带来的高吞吐特性,又引入轻量级串行模块,逐词元注入前缀依赖信息。该模块提供两种实现方式:一种是仅依赖前一词元的马尔可夫头,另一种是通过循环状态持续累积完整前缀信息的RNN头。
实验验证显示,在同等模型深度条件下,仅两层Transformer结构的DSpark,在全部测试任务中均超越五层结构的DFlash模型所达到的接受长度。
目前,DSpark已集成至DeepSeek-V4在线服务系统,并基于真实用户请求流量完成性能实测。结果表明,在保持相同吞吐量的前提下,相较现有生产环境基线系统MTP-1,用户端文本生成速度提升幅度达百分之六十至百分之八十五。
此外,DSpark已在多个第三方模型上完成适配验证。以Qwen3系列模型为例,在四亿参数、八亿参数与十四亿参数三种规格下,相比自回归草稿方案,单轮平均可接受词元长度分别提升百分之三十点九、百分之二十六点七与百分之三十;相比并行草稿方案,则分别提升百分之十六点三、百分之十八点四与百分之十八点三。



















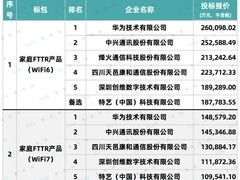








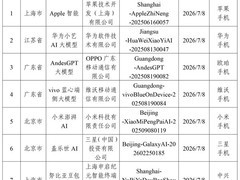




































评论
更多评论