
2026年5月28日,SuperCLUE发布最新一期中文大模型综合能力评测报告。结果显示,全球领先位置仍由海外主流模型占据,四款国际模型稳居前四,构成稳固的第一梯队;国产模型中表现最优的三款则在第五名左右展开激烈角逐,共同组成国内第一方阵。
本次评测涵盖21款国内外主流大模型,评估维度覆盖数学推理、科学推理、代码生成、智能体任务规划、精确指令遵循与幻觉控制六大方向,共计492道测试题。
Gemini、GPT-5.5、Claude-Opus及Gemini-Flash四款海外模型凭借全面而稳定的性能,持续保持前四排名,暂未出现位次变动。DeepSeek-V4-Pro、Qwen3.7-Max与豆包Seed 2.0 Pro三款国产模型得分高度接近,全球综合排名均落在第五位附近,代表当前国产大模型的最高水平。
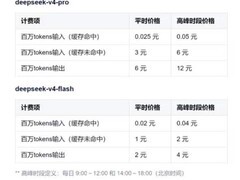
尽管与国际顶尖水平尚存一定距离,但国产模型进步显著。在代码生成任务中,Qwen3.7-Max仅落后于头部海外模型不到2分;数学推理与科学推理等高难度项目中,亦多次进入全球前列。成本效益方面,国产模型优势明显,多款产品以更低的部署与运行成本,实现接近国际领先水平的实际效果。而在推理效率维度,高性能区间仍主要由海外模型主导,国产模型多数处于中低效能区间,具备进一步优化空间。
总体而言,国产大模型正以较快节奏缩小与全球第一梯队的差距,但目前头部格局尚未发生根本性变化。






























































评论
更多评论