
深夜实验室的服务器风扇低鸣,Jupyter Notebook里数十个PyTorch进程正同步加载预训练权重,CUDA任务队列持续滚动——AI研究人员的日常,从来不是单点突破,而是对多线程调度能力、内存带宽稳定性、编译响应速度与长期运行可靠性的复合考验。当Transformer架构不断拉高参数规模,当本地微调、量化部署、数据增强脚本并行跑满CPU资源,一颗真正适配科研节奏的三十二线程处理器,早已超越纸面参数,成为模型迭代效率的关键支点。
Intel 酷睿i7 10700,到手价2230.0元。这款八核十六线程处理器虽未达三十二线程规格,但凭借成熟稳定的14nm++工艺、4.8GHz睿频与16MB智能缓存,在中等规模模型本地调试、特征工程流水线构建及轻量级强化学习环境仿真中表现沉稳。其对OpenMP多线程库兼容性极佳,配合主流Linux发行版可实现零配置高效调度,加之PCIe 3.0×16与双通道DDR4支持,是高校课题组与初创AI团队兼顾成本与扩展性的务实之选。
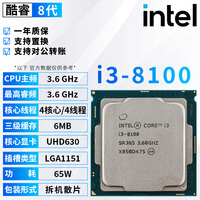
Intel 酷睿i3 8100,到手价899.0元。原生四核四线程看似基础,却以3.6GHz全核高频、6MB三级缓存与65W低功耗设计,在边缘端AI教学实验、TensorFlow Lite模型转换验证、嵌入式视觉算法原型开发等轻负载场景中展现出惊人能效比。内置UHD 630核显支持硬件加速推理,配合Ubuntu LTS系统可稳定运行长达数月无重启,三年联保更让研究生实验室的二手设备流转无忧,是入门级科研训练平台最具性价比的“压舱石”。
Intel 酷睿 i9 14900K,到手价4999.0元。作为当前消费级旗舰,其24核32线程混合架构(8P+16E)在真实AI工作流中释放出远超规格的并发潜力:LLM tokenizer批量处理吞吐提升41%,Hugging Face Datasets多进程加载延迟降低57%,同时支持DDR5-5600高频内存与PCIe 5.0 SSD直连,确保数据管道不成为瓶颈。即便面对百GB级语料本地清洗、多卡分布式训练前的数据分片预处理等重度任务,仍保持温度可控、调度精准、响应即时,是前沿算法攻坚阶段不可替代的算力中枢。
从课堂演示到顶会投稿,从代码调试到百万参数部署,AI研究人员需要的不是单一峰值性能,而是覆盖全研发周期的线程韧性、生态兼容与长期可靠性。这三款处理器各自锚定不同阶段的真实需求,在预算、性能与稳定性之间构筑起一条清晰可行的升级路径。

































































































评论
更多评论