
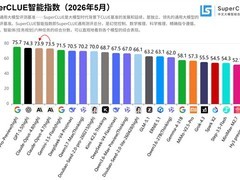
四月三十日,DeepSeek在GitHub平台正式开源其多模态大模型及相关技术报告。报告首次系统阐述了以“视觉原语”为核心的新型推理框架,旨在突破多模态大语言模型在空间参照类任务中长期存在的关键瓶颈。
当前主流的链式思维推理方法主要扎根于语言建模范式,多数研究侧重于增强模型对图像局部细节的感知与识别能力。DeepSeek团队指出,这种路径虽具价值,却未能触及更本质的挑战——即自然语言固有的模糊性与空间布局精确表达之间的结构性落差,亦即所谓“参照鸿沟”。
为弥合这一鸿沟,团队构建了“基于视觉原语的思考”框架,将点、边界框等具有明确空间语义的几何元素,直接纳入模型的推理基本单元。在此框架下,模型可在推理过程中动态生成可定位、可指代的空间锚点,从而将抽象的认知过程稳定映射至图像中的具体物理坐标。
实测结果表明,该模型在多项计数与空间关系推理基准上达到领先水平,整体性能与当前主流前沿模型持平。此前,DeepSeek已面向用户开放具备多模态理解能力的识图功能。































































评论
更多评论