
感谢热心网友提供的线索!以下是关于 DeepSeek“开源周”第三天的重要进展的详细介绍。
2月26日,DeepSeek“开源周”的活动进入了第3天,今日重点推出了一款支持稠密和混合专家模型(MoE)的 FP8 矩阵乘法(GEMM)库。这款工具旨在为 V3/R1 模型的训练和推理提供技术支持。以下是该工具的主要特点:
- 在 NVIDIA Hopper GPU 上,该库能够实现超过 1350 FP8 TFLOPS 的高性能表现。
- 代码设计简洁,易于理解,无需复杂依赖,适合开发者学习和使用。
- 完全基于即时编译技术(Just-In-Time),在安装过程中无需预编译步骤。
- 核心代码量仅约 300 行,却在大多数矩阵尺寸下超越了经过高度优化的内核性能。
- 支持密集布局以及两种 MoE 布局,适应多种应用场景。
开源链接如下:
https://github.com/deepseek-ai/DeepGEMM
官方对 DeepGEMM 的介绍如下:这是一个专门为高效且清晰的 FP8 通用矩阵乘法设计的库,集成了 DeepSeek-V3 提出的精细化缩放能力。它不仅支持普通的 GEMM 运算,还兼容 Mix-of-Experts (MoE) 分组 GEMM。
DeepGEMM 基于 CUDA 开发,采用轻量级即时编译(JIT)模块,在运行时动态编译所有内核。目前,该库仅支持 NVIDIA Hopper 张量核心。为了解决 FP8 张量核心累加可能带来的精度损失问题,DeepGEMM 引入了 CUDA 核心的两级累加方法进行优化。虽然其设计理念借鉴了 CUTLASS 和 CuTe 的部分思路,但并未深度依赖它们的模板或代数结构。
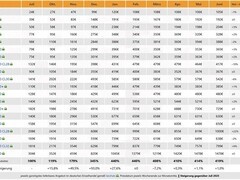
尽管设计简洁,DeepGEMM 的性能表现优异,在多种矩阵形状下的测试结果与专家优化的库相当,甚至更优。在 NVIDIA H800 平台上,使用 NVCC 12.8 对 DeepSeek-V3/R1 推理中涉及的各种矩阵形状(包括预填充和解码阶段,但不包含张量并行)进行了测试。所有加速指标均以内部优化的 CUTLASS 3.6 实现作为基准进行对比。
需要注意的是,DeepGEMM 在某些特定矩阵形状下的表现仍有提升空间。官方欢迎有兴趣的开发者提交优化方案,共同推动该项目的发展。
































































评论
更多评论