
近期,多家美国科技企业正逐步将中国开源人工智能大模型部署至核心生产系统。这一趋势与主流商业模型服务价格持续走高密切相关。
以加密货币交易所为例,其已将智谱推出的GLM 5.2与月之暗面研发的Kimi K2.7确立为全体工程师日常使用的默认大模型。这一调整通过内部大语言模型网关完成,未对工程师的调用额度作出限制,却显著降低了整体AI运营成本。
该公司首席执行官在社交平台公开表示,在模型调用量呈指数级增长的背景下,通过更换默认模型、优化请求路由策略以及增强缓存机制,AI相关支出已减少近百分之五十。他指出,该路径不依赖特殊技术门槛或定制化基础设施,具备广泛适用性,其他企业亦可依循类似方式实现成本优化。
值得注意的是,此次调整并未削减工程师原有Token配额。数据显示,九成以上的工程师此前从未达到其调用上限。因此,公司仅将代码审查、技术文档摘要等常规开发任务所依赖的默认模型,由原先采用的国际头部闭源模型,平稳切换至上述两款中国开源模型。
此前,已有企业实施同类策略:一家全球在线住宿平台将客户服务系统所用模型由GPT系列替换为通义千问;另一家专注AI工作流自动化的企业亦将核心模型由Claude迁移至DeepSeek V4,主要原因在于其AI支出已超出人力薪酬总和。另有云数据平台企业测算显示,GLM 5.2在多项关键指标上表现接近Claude,而单位调用成本明显更低。
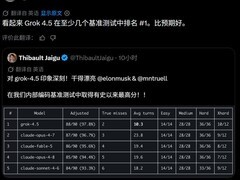
在主流大模型调用平台的文本生成类榜单中,中国开源模型长期稳居前列。DeepSeek、小米MiMo、MiniMax、腾讯混元及智谱GLM等均处于第一梯队,反映出其在实际应用场景中的稳定性和成熟度。




























































评论
更多评论