
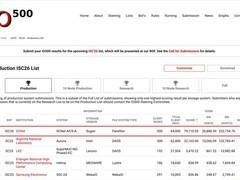
近期,英特尔与超微联合推出完整的ACE CPU扩展规范。这一面向人工智能运算的全新指令集已正式集成至x86架构,核心目标是通过深度优化矩阵乘法运算,显著提升能效比与计算密度,从而切实降低在通用处理器上本地部署和运行AI模型的技术门槛。
当前,多数日常AI推理任务依赖独立显卡完成。然而,在轻量级模型部署、低延迟响应场景,或缺乏独立显卡的设备中,直接利用CPU进行推理更具现实优势。但传统AVX10向量指令并非专为矩阵运算设计,在执行AI负载中最关键的矩阵乘法时,普遍存在功耗偏高、执行效率不足的问题。
ACE指令集在保留现有AVX10寄存器结构的基础上进行拓展,新增专用硬件单元专责处理矩阵运算任务。其设计无需重构底层微架构,使芯片厂商能够以较低成本完成适配。
根据公开技术指标,在相同输入向量规模下,ACE的计算密度可达AVX10的16倍。单条指令可承载更多计算操作,有效减少指令调度次数,同步提升内存带宽利用率,并实现更优的功耗控制。需注意的是,16倍计算密度并不等同于整体性能提升16倍,最终实际表现仍取决于各厂商后续处理器的具体硬件实现。
该指令集采用跨厂商统一标准,开发者只需编写一次代码,即可在所有支持ACE的英特尔与超微处理器上原生运行,彻底摆脱以往需为不同AVX版本分别适配的繁琐流程。主流AI框架如PyTorch与TensorFlow均具备开箱即用的兼容能力。数据类型方面,全面支持INT8、FP8、BF16等AI常用精度格式,并原生集成OCP MX块缩放机制,弥补了AVX10在AI运算支持上的关键功能缺位。
对开发实践而言,部分原本需调用专用NPU单元的临时性算力需求, now可平滑迁移至CPU处理,无需再适配规格各异、生态割裂的第三方NPU硬件。随着新一代x86处理器陆续集成ACE扩展,笔记本电脑、台式机及服务器平台即便不配备独立显卡,亦能高效支撑多样化本地AI应用,有力推动端侧AI在更多现实场景中的规模化落地。































































评论
更多评论