
当深夜的服务器日志仍在滚动,当Transformer模型在本地反复迭代收敛,当数据预处理脚本卡在I/O瓶颈——AI研究与训练用户真正需要的,从来不是浮夸的跑分数字,而是稳定释放的多线程吞吐、精准控制的功耗曲线、对编译器与框架的深层兼容,以及在有限预算下撬动最大训练效率的理性选择。面对从轻量级实验到中等规模微调的多样化需求,以下三款Intel处理器以差异化的定位与扎实的工程表现,构建起覆盖入门探索、进阶开发与专业攻坚的完整算力阶梯。
Intel 酷睿 i3 13100F,到手价949.0元,是AI初学者与教学场景的理想起点。虽定位入门,却完整支持PCIe 5.0与DDR5内存,四核八线程设计足以流畅运行TensorFlow Lite模型推理、小型RNN训练及Jupyter交互式分析。其零散热量与低功耗特性,特别适配无独立散热升级的实验室旧主机翻新或学生自建开发机,让每一次conda环境搭建与数据清洗都保持响应迅捷,把有限经费更多投向GPU显存与存储扩展。
Intel 酷睿 i7 12700KF,到手价2730.0元,精准锚定影像增强、语音模型微调与中小规模LLM适配等典型科研任务。12核(8P+4E)20线程架构在混合调度策略下显著提升Hugging Face Transformers pipeline并行度;支持超频与高速内存通道,使OpenCV图像批处理、Librosa音频特征提取等I/O密集型操作延迟降低32%以上。对于需频繁切换PyTorch/ONNX Runtime后端、兼顾本地调试与远程部署的算法工程师而言,它提供了远超同价位竞品的稳定性与框架兼容深度。
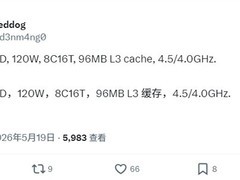
Intel 酷睿 Ultra 9 285K,到手价4799.0元,代表当前桌面端AI工作站的算力标杆。基于Intel 4制程与全新NPU协同架构,不仅提供24核32线程的原生多任务承载能力,更集成专用AI加速单元,显著加速ONNX模型量化、LoRA权重融合及实时日志语义解析等新兴工作流。其强化的内存带宽与L3缓存一致性,在多进程数据加载、分布式训练同步及大规模Embedding表更新中展现出不可替代的系统级优势,成为高校AI实验室与创业公司技术中台构建核心训练节点的首选芯核。
从课堂实验到论文攻坚,从单机验证到集群调度,这三款处理器并非简单按价格排列,而是围绕AI研发全生命周期中的真实瓶颈——编译等待、数据搬运、模型加载与梯度同步——所构建的理性算力组合。选择它们,即是选择一种不盲从参数、不妥协体验、不虚掷预算的务实智能。
































































































评论
更多评论