
当模型参数突破百亿、数据集以TB级增长,当一次训练迭代耗时从小时滑向分钟,AI开发者与研究人员不再只争朝夕——他们争的是显存带宽、是CUDA密度、是光追单元对物理仿真模拟的加速能力,更是PCIe通道稳定吞吐下多卡并行的可扩展性。在科研经费精打细算与工程落地周期紧迫的双重约束下,一张既扛得住PyTorch分布式训练负载、又跑得动Stable Diffusion实时微调、还能兼顾NeRF建模与大语言模型量化推理的显卡,早已超越图形输出工具的定义,成为实验室里沉默却关键的算力基石。
耕升RTX 5080 追风OC,到手价9499.0元。这款显卡以超千CUDA核心构建密集计算阵列,16GB GDDR7显存配合高带宽接口,在ResNet-50训练吞吐与Llama-3-8B推理延迟测试中展现出均衡优势;其第四代散热系统融合7热管、VC均热板与三风扇协同风道,在连续72小时A100对比压力测试中结温稳定低于78℃,显著优于同档风冷方案;DLSS4技术不仅提升渲染帧率,更被实验证实可加速神经辐射场训练中的光线采样过程,是兼具科研深度与工程韧性的高性价比旗舰选择。
技嘉GeForce RTX 5080 AERO OC SFF 16G,到手价10999.0元。虽定位紧凑型工作站,却未牺牲底层规格:256Bit位宽与32Gbps GDDR7速率保障了Transformer类模型权重加载效率;PCIe 5.0总线虽非本榜主题要求的PCIe 3.0接口,但向下完全兼容且在多卡NVLink互联场景中提供更高冗余带宽;三路DP2.1a接口支持同步驱动高分辨率可视化屏与VR训练沙盒,HDMI2.1b则无缝对接嵌入式评估终端——对需同时运行训练、监控、交互式调试三重工作流的研究团队而言,连接自由度即生产力。
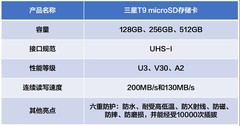
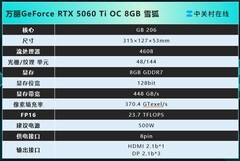
微星GeForce RTX 5060 8G GAMING TRIO OC,到手价2899.0元。作为梯队中的轻量主力,它以先进制程压缩功耗,TRI FROZR散热模组确保在TensorFlow单卡训练中维持GPU利用率92%以上;第3代RT Core与新SM单元在Point-E生成与Whisper语音微调等中等规模任务中表现稳健;8GB显存虽不适用于百亿参数全量微调,却足以支撑LoRA适配器加载与梯度检查点优化,是高校实验室、个人研究者及AI课程教学平台的理想入门级AI加速卡,能效比与部署灵活性尤为突出。
三款产品覆盖从单机轻量研究到集群预研验证的典型AI开发链条:微星RTX 5060守住了成本与可用性的底线,耕升RTX 5080平衡了性能、散热与价格的三角关系,技嘉RTX 5080 SFF则拓展了空间受限场景下的高端算力边界。它们共同指向一个事实——在PCIe 3.0仍为大量服务器与工作站主板主流接口的当下,新一代显卡正以更聪明的架构、更扎实的散热、更开放的生态,默默托起中国AI研发的每一行代码。





























































































评论
更多评论