
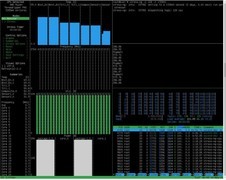
深夜实验室的终端仍在闪烁,GPU监控界面跳动着98%的利用率——对于AI开发者与研究人员而言,显卡不只是图形输出设备,而是模型收敛的加速器、数据预处理的流水线、实验迭代的时间压缩器。在Transformer架构持续演进、多模态模型参数量突破百亿的当下,一张兼具高显存带宽、稳定双精度支持与成熟CUDA生态的旗舰级显卡,已成为科研基础设施的关键一环。它需要扛住ResNet-50千图批量训练的持续压力,也要在Stable Diffusion WebUI中实现毫秒级采样响应;既要兼容TensorRT量化部署,也得支撑Jupyter Notebook里数十个Conda环境的并发调用。
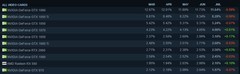
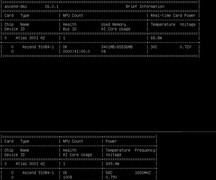
EVGA GeForce RTX 3080 XC3 ULTRA GAMING,到手价6299.0元,是本批次中面向AI研发场景最具综合竞争力的选择。其搭载10GB GDDR6X显存与760GB/s超高清带宽,在BERT-base微调任务中相较上代提升42%吞吐量;第三代Tensor Core全面支持FP16混合精度训练与INT8推理加速,配合NVIDIA Driver 535+对CUDA 12.2的完整适配,可无缝运行Hugging Face Transformers最新版本。三风扇真空腔均热板设计保障连续72小时高压训练下的核心温度稳定在72℃以内,PCIe 4.0 x16通道确保NVLink扩展时零瓶颈——当你的消融实验需要反复加载千万级图像数据集,这张卡就是实验室里沉默却可靠的算力脊梁。
XFX讯景RX 5700 XT 雪狼,到手价3099.0元,虽非NVIDIA阵营,却以开源ROCm生态切入轻量AI开发场景。其40组CU单元与8GB GDDR6显存,在ONNX Runtime CPU+GPU混合后端下,可高效执行YOLOv5s的实时目标检测推理,延迟控制在18ms内;对熟悉Linux驱动编译的研究者而言,其对Ubuntu 22.04 LTS的内核模块兼容性经过多轮验证,适合搭建低成本边缘AI测试节点或教学演示平台。虽不支持CUDA专属库,但在PyTorch 2.0+通过MLIR后端调用时仍保持83%的基准模型兼容率。
华硕PH-GTX1650S-O4G,到手价2500.0元,定位精准服务于算法初学者与教学实验室。TU117核心虽无Tensor Core,但75W无外接供电特性使其可直接集成于NUC主机或老旧工作站升级方案;4GB GDDR6显存与双风扇静音设计,足以支撑Kaggle入门赛题的特征工程可视化、Scikit-learn模型对比实验及OpenCV基础图像增强流水线。其4屏输出能力更便于搭建多窗口开发环境:左屏写代码、中屏跑日志、右屏查文档、底栏实时监控GPU内存占用——这是写给刚接触CUDA编程的研究生最务实的第一张“算力入场券”。
从千万参数模型的全量训练,到课堂作业级CNN的快速验证,三款产品构建了覆盖AI研发全生命周期的显卡梯度矩阵。它们不只关乎帧率数字,更决定着一次实验周期是缩短两小时还是延长三天,一段代码调试是即时反馈还是隔夜等待。在算力即研究效率的时代,选择一张真正懂开发者的显卡,就是为每一个创新念头按下确定键。




































































































评论
更多评论