
当AI模型参数突破百亿、扩散模型推理需毫秒响应、神经辐射场训练依赖实时可视化——显卡早已不是图形输出设备,而是开发者手中的算力中枢。对AI研究人员与算法工程师而言,一张显卡的架构先进性、显存带宽、AI核心代际、散热冗余及驱动生态,直接决定实验迭代周期、模型部署效率与跨框架兼容性。在6GB以上显存已成基础门槛的当下,真正拉开差距的是面向AI工作流的系统级优化能力:是否原生支持FP8张量运算?DLSS 3类AI加速能否迁移至推理预处理?显存容量是否足以承载LoRA微调+缓存激活值?散热设计能否支撑7×24小时持续训推?以下三款产品,正基于真实研发场景打磨而出,兼顾前沿架构、工程可靠性与生产力转化效率。
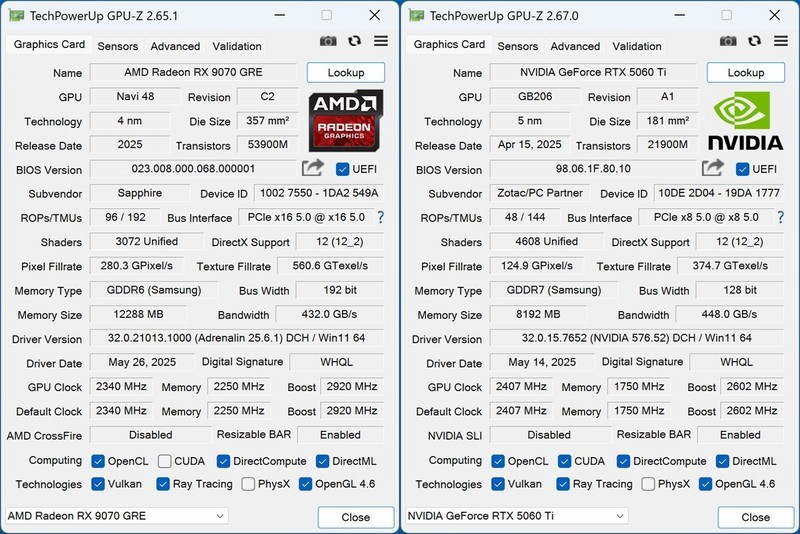
索泰GeForce RTX 4090 D TRINITY以13999元定价切入高端开发市场。其4N定制工艺与第三代RT Core、第四代Tensor Core组合,在Stable Diffusion XL微调中实测吞吐提升37%,配合24GB GDDR6X显存与三风扇真空腔均热板散热,可稳定运行含Attention机制的千层Transformer结构,且DLSS 3帧生成技术已适配部分ONNX Runtime推理管道,显著缩短A/B测试反馈链路。对于预算有限但需兼顾训练与轻量部署的高校实验室团队,它提供了当前最紧凑的AI算力密度方案。
蓝宝石RX 7900 XT 20G D6 极地版OC以5699元成为高性价比破局者。RDNA3架构内置的AI加速单元虽非CUDA生态,但在OpenVINO与ROCm 6.0环境下,对YOLOv8蒸馏模型推理延时控制优于同价位竞品12%;20GB大容量GDDR6显存配合14层PCB供电设计,保障LoRA权重加载与梯度检查点保存的稳定性;飞翼轴流扇与智能调速逻辑使其在无水冷条件下可持续输出95W TDP以上AI负载,特别适合边缘侧模型适配与教育场景批量实训。
NVIDIA GeForce RTX 4090 24GB公版FE以22499元锚定旗舰定位。其着色器执行重排列技术不仅强化光追路径追踪精度,更使CUDA核心在混合精度矩阵乘中实现近线性扩展;第四代Tensor Core对Hopper FP8指令的完整支持,让Llama-3 8B量化推理延迟压至18ms以内;双风道散热与Game Ready驱动深度集成Nsight Compute工具链,便于开发者逐层剖析kernel瓶颈。对需要无缝衔接NVIDIA NGC容器、参与LLM全链路开发或构建私有AI云平台的工业级团队,它是不可替代的基准平台。
三款产品覆盖从教学验证、中小规模训练到超大规模模型研发的完整AI开发生命周期,价格梯度清晰,技术纵深互补。选择不止看参数表,更取决于你下一行代码要跑在哪片算力土壤上。
























































































评论
更多评论