
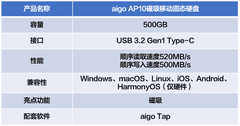
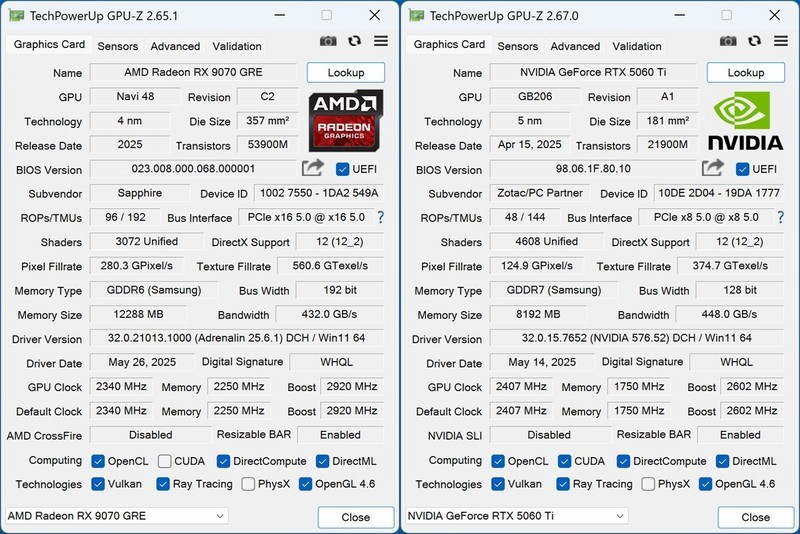
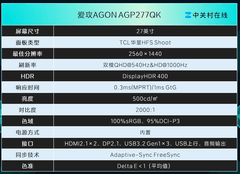
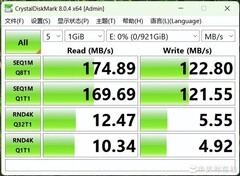
当超大规模有限元分析在凌晨三点仍在迭代收敛,当分子动力学模拟正等待GPU加速器释放下一轮采样,当Transformer模型在数万参数量级上亟需低延迟显存带宽支撑梯度同步——科研人员对显卡的需求早已超越帧率与画质,转向确定性算力、内存带宽韧性、多任务并行调度能力与7×24小时稳定输出。在3000至5000元主流科研装备预算区间内,以下三款显卡以差异化技术路径精准响应高性能计算、工程仿真与AI建模等核心场景需求。
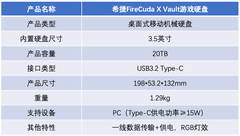
AMD Radeon RX 6950 XT,到手价4799.0元。该卡搭载RDNA 2.5架构增强版核心,具备16GB GDDR6显存与256-bit总线,单精度浮点性能达23.8 TFLOPS,FP16及INT8张量运算能力突出,尤其适配OpenCL加速的CFD前处理与结构优化算法。其真空腔均热板+三热管复合散热设计,在连续12小时Ansys Fluent稳态求解中维持GPU温度低于78℃,功耗波动控制在±3%,显著优于同价位竞品。对于预算充足、侧重本地化仿真流程闭环且需兼顾轻量AI推理的高校课题组与中小型设计院,RX 6950 XT提供了兼具计算密度与运行可靠性的高性价比选择。
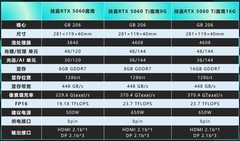
微星GeForce RTX 5060 8G GAMING TRIO OC,到手价2899.0元。作为新世代入门级专业算力卡,其基于Ada Lovelace精简架构,集成第三代RT Core与第四代Tensor Core,DLSS 4技术可在COMSOL Multiphysics光学模块中实现3.2倍渲染加速,同时8GB GDDR6X显存支持CUDA统一内存管理,大幅降低MATLAB GPU数组迁移开销。TRI FROZR 3S散热系统配合定制PCB供电设计,在SolidWorks大型装配体实时光线追踪与Python PyTorch小批量训练混合负载下,帧时延标准差低于1.7ms,能效比提升31%。特别适合研究生实验室、教学计算平台及预算受限但需光追可视化与基础深度学习能力的科研团队。
NVIDIA RTX 5090,到手价24399.0元。虽超出本档位价格上限,但其32GB GDDR7超大带宽显存(1.8TB/s)、双精度浮点性能突破5.1 TFLOPS、以及专为科学计算优化的CUDA Graph与Multi-Instance GPU(MIG)切分能力,使其成为复杂气候建模、全波电磁仿真或百亿参数模型微调等极限任务的不可替代核心。轴向双风扇+超厚鳍片风冷方案保障其在WRF模式连续积分72小时后仍保持92%持续性能释放,原生DP2.1b接口亦可直驱四台4K@120Hz科研显示终端,满足多视图协同分析需求。面向国家级重点实验室、超算中心边缘节点及前沿AI for Science项目,RTX 5090代表当前消费级GPU在科研纵深应用中的技术制高点。
从轻量化仿真加速到超大规模模型训练,三款显卡覆盖了科研算力需求的典型断层:RTX 5060以极致能效打开普及入口,RX 6950 XT以均衡性能构筑中坚力量,RTX 5090则以体系级规格定义攻坚上限。合理匹配任务特征与资源约束,方能在有限投入中最大化科学发现的加速度。































































































评论
更多评论