
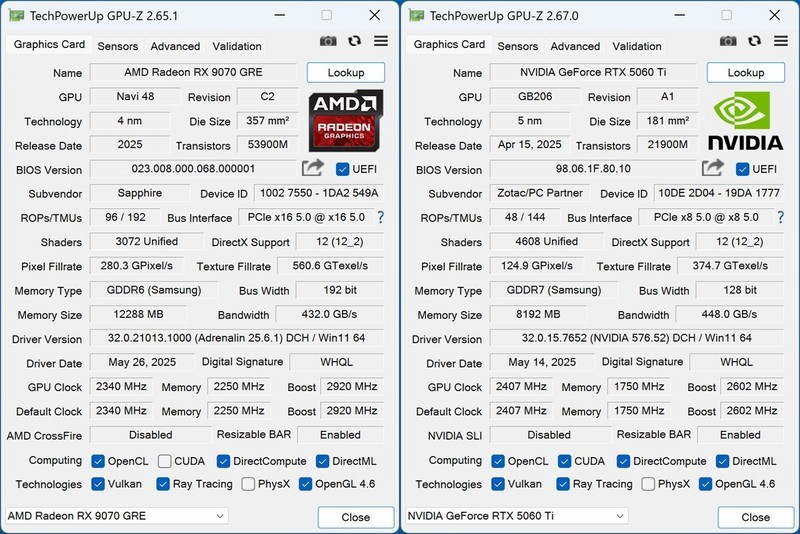
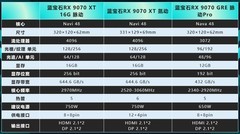
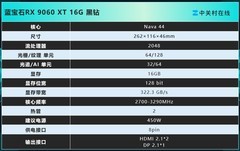
当模型参数突破千亿、扩散生成耗时压缩至秒级、神经辐射场实时重建成为日常,AI开发者与研究人员手中的显卡早已不止是图形加速器,而是算法迭代的算力基石、实验验证的时间刻度、科研落地的效能支点。面对不同阶段的研究需求——从高校实验室的轻量推理验证,到企业研究院的多模态大模型训练,再到工业级数字孪生的实时渲染推演——显卡选型必须兼顾架构先进性、显存带宽冗余度、多卡协同稳定性与长期投入产出比。
NVIDIA RTX A6000显卡以38499.0元的到手价,树立了科研级显卡的新标杆。其4nm制程与Ada架构深度融合,18176个CUDA核心配合48GB超大容量GDDR6显存,带来单卡16TFLOPS的稳定单精度算力与前代6倍的光线渲染吞吐。第三代RT Core与第四代Tensor Core协同优化,使混合精度训练、FP8量化推理、神经渲染管线全链路加速成为可能;PCIe 4.0高带宽通道与NVLink多GPU技术更保障了百层Transformer模型分布式训练的通信效率,是高校重点实验室、AI研究院及头部科技企业核心训练集群的理想选择。
NVIDIA RTX 5090以24399.0元的定位切入高性能创作与中等规模AI研发场景。全新架构在保持能效比优势的同时,显著提升张量核心密度与显存带宽利用率,4K分辨率下可流畅运行Stable Diffusion XL微调、Llama-3-8B本地推理、NeRF建模与实时物理仿真。其对CUDA Graph、Multi-Instance GPU(MIG)等开发工具链的原生支持,让研究人员无需深度定制驱动即可快速部署多任务实验环境,在控制成本前提下获得接近A系列的专业表现,特别适合快速原型验证与跨学科联合项目。
铭瑄 GT 710重锤PLUS 2G则以299.0元极富竞争力的价格,为教育机构机房、学生个人工作站及老平台AI教学实验提供切实可行的入门方案。2GB显存虽不适用于大模型训练,却足以支撑TensorFlow/PyTorch基础框架运行、OpenCV图像处理流水线加速、以及Jupyter Notebook中轻量级神经网络调试。被动散热设计实现零噪音运行,VGA/DVI/HDMI全接口兼容老旧显示终端,三年质保大幅降低运维门槛,是AI通识课程、嵌入式视觉入门与边缘计算教学的理想硬件载体。
三款产品覆盖从教学普及、工程验证到前沿科研的完整AI开发生命周期,既可独立部署亦可分层组合。无论身处高校讲台、实验室工位还是初创公司服务器机柜,合理匹配算力层级,才能让每一次反向传播更高效,每一帧神经渲染更真实,每一轮算法迭代更笃定。




































































































评论
更多评论