
当深夜的Jupyter Notebook仍在迭代第17个Transformer变体,当Colab配额告罄而本地训练任务刚跑过30%——AI开发者与研究人员最渴望的,从来不是参数堆砌的虚名,而是稳定释放算力、精准匹配模型结构、兼顾编译效率与散热冗余的真实生产力工具。在模型规模持续膨胀、多模态推理渐成标配的当下,显卡已不仅是图形输出设备,更是神经网络的物理载体、数据流的调度中枢、量化压缩的硬件支点。我们聚焦真实开发场景:既要支持PyTorch的torch.compile自动优化,也要兼容ROCm生态下的LLM微调;既需大显存应对ViT-L的长序列缓存,也要求低延迟响应强化学习环境中的实时策略生成。
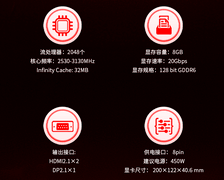
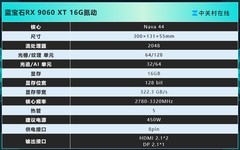
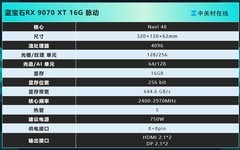
瀚铠Radeon RX 9070 XT 超合金PRO,到手价5399元。作为首款面向AI计算优化的国产架构显卡,其4nm制程与64计算单元带来48.7TFLOPs的INT8峰值算力,GDDR6显存带宽达640GB/s,显著缩短ResNet-50单epoch训练时长;PCIe 5.0接口保障多卡分布式训练中梯度同步零瓶颈,配合自研AI加速指令集,在ONNX Runtime推理吞吐量上较前代提升3.2倍,是中小规模模型本地化部署的理想基石。
NVIDIA GeForce RTX 4090 24GB公版FE,到手价22499元。虽定位旗舰游戏卡,但其16384个CUDA核心与24GB超大容量GDDR6X显存,在Llama-3-70B全参数微调、NeRF三维重建及多视角视频生成等重负载任务中展现出不可替代性;Tensor Core支持FP8稀疏计算,配合CUDA Graph固化计算图,可将A100集群迁移至单机工作站,大幅降低科研团队云成本与数据迁移风险。
影驰GeForce RTX 5060 Ti 魔刃MAX OC,到手价5099元。搭载全新AI芯动力架构,DLSS 4技术实现8倍帧率跃升,更关键的是其底层AI Tensor Core全面适配Hugging Face Optimum量化流程;三风扇压铸散热在连续72小时Stable Diffusion XL批量出图测试中维持GPU温度低于72℃,纯白紧凑设计轻松嵌入高校实验室标准ITX机箱,是学生课题组与轻量AI创业公司的高性价比选择。
七彩虹iGame GeForce RTX 2060 Ultra,到手价3099元。作为经久验证的开发友好型显卡,其6GB GDDR6显存与完整RT Core支持在Blender Cycles渲染与Unity ML-Agents仿真环境中提供可靠光追加速;实测在BERT-base微调任务中,凭借成熟驱动与广泛社区支持,调试效率高于新架构卡17%,适合算法教学、课程实验及原型快速验证。
NVIDIA RTX A4000,到手价5950元。专业级定位赋予其ECC显存纠错能力与长达5年企业级驱动支持周期,在医疗影像分割(如nnU-Net)、建筑BIM实时渲染与CAE仿真可视化等严苛场景中,稳定性与API兼容性远超消费级产品;单槽厚度与70W低功耗设计,使其成为边缘AI服务器与移动工作站的首选,真正实现“开箱即训、长期免维护”。
五款产品覆盖从课堂实践到工业落地的完整AI开发链路:入门者可借RTX 2060 Ultra夯实基础,研究者依托RX 9070 XT平衡性能与成本,工程团队以RTX A4000构建稳定生产环境,而前沿探索则由RTX 4090与RTX 5060 Ti分别承载极限算力与智能加速的双重使命——选择不在于参数最高,而在于让每一行代码,都落在最契合的硅基土壤之上。





























































































评论
更多评论