
12月23日,一位因揭露硅谷血液检测企业Theranos造假事件而广受关注的调查记者,于当地时间本周一在加州联邦法院提起诉讼,将xAI、Anthropic、谷歌、OpenAI、Meta以及Perplexity列为被告,指控这些科技公司未经授权使用受版权保护的书籍内容,用于训练其人工智能系统。
该记者为纽约时报资深撰稿人、畅销书坏血作者约翰•卡里鲁。此次诉讼由他联合另外五位作家共同发起,主张上述企业在开发大语言模型(LLMs)过程中,擅自复制其作品,并将其纳入聊天机器人的训练数据集,构成对著作权的直接侵犯。
这起案件是近年来一系列针对人工智能训练数据来源合法性争议中的最新一起,也是首例明确将xAI纳入被告行列的版权纠纷。与此前多起集体诉讼不同,本案原告方主动选择不参与集体索赔机制,而是以独立身份提出主张。他们认为,集体诉讼模式易被企业利用,仅需达成单一协议即可化解大量侵权责任,削弱了对个体创作者权利的充分保障。
诉状中强调:“大型语言模型公司不应通过低成本和解方式,轻而易举地消解成千上万起具有高价值的版权侵权追责。”
今年8月,Anthropic曾就类似争议达成一项重要和解协议,同意向部分作家支付15亿美元,以解决有关其非法获取数百万册图书用于AI训练的指控。然而本案原告指出,在该和解方案下,每位作者每部作品所获赔偿尚不足版权法规定的单部作品最高赔偿金额15万美元的2%,补偿程度极为有限。
本次诉讼由弗里德曼•诺曼德•弗里德兰律师事务所代理,团队成员包括凯尔•罗奇。值得注意的是,在去年11月有关Anthropic案件的听证过程中,美国联邦地区法院法官威廉•阿尔苏普曾对罗奇参与创办的另一家律所提出批评,指其试图动员作家退出集体和解,谋求更高赔付。
在此前的相关听证会上,卡里鲁曾向法庭明确表示,以未经授权的方式窃取书籍内容来构建人工智能系统,是此类公司难以回避的“原罪”,而现有的和解安排远不足以弥补创作者遭受的损失。



























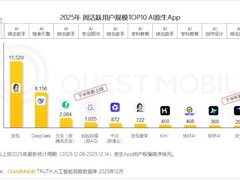




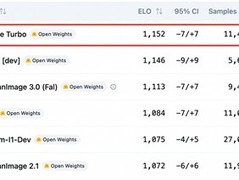


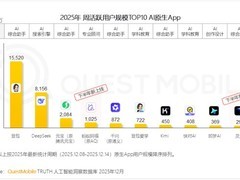




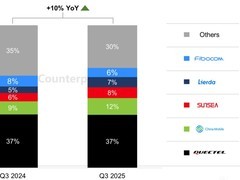













评论
更多评论