
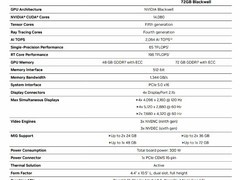
12月17日,字节跳动Seed团队推出全新音视频创作模型Seedance 1.5 pro。该模型为音视频联合生成系统,具备精准理解复杂镜头指令的能力,可同步生成高质量画面与叙事音频,实现音画一体的高效内容制作。
新模型在音频生成方面支持多样化人声与音效输出,中文语音表达自然流畅,涵盖部分方言类型。通过优化音画同步技术,显著提升了人物口型与语音的匹配度,动作与声音的协调性更为出色。整体音质清晰稳定,具备良好的空间层次感,能够根据画面节奏与情绪变化进行动态适配,增强叙事的连贯性与沉浸感。
在视频表现上,模型可完成复杂运镜设计,并在叙事逻辑下智能补充合理的主体行为与场景元素。特写镜头注重细节刻画,通过微表情的精准呈现延续情感脉络。画面在构图、光影与氛围营造方面体现出自然协调的影视化美学风格。
Seedance 1.5 pro还具备基于提示词构建基础叙事结构的能力,在人物情绪、面部表情、肢体动作与声音表达之间实现高度统一,确保视听语言的一致性与完整性。该模型适用于短剧创作、商业广告及社交媒体内容等多种应用场景。
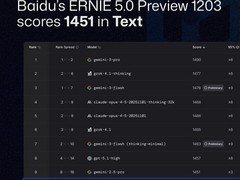
目前,该模型已接入“即梦 AI”与“豆包”平台,正式向公众开放使用。据团队介绍,在多项综合评估中,Seedance 1.5 pro的核心性能指标已达到行业领先水平。



























































评论
更多评论