
马斯克与xAI团队的三位技术负责人,于北京时间2月18日12点30分左右发布了最新推出的Grok-3基座大模型。这款大模型在数学和科学推理方面表现出色,展示了卓越的代码创作能力,并公布了后续的开源计划。
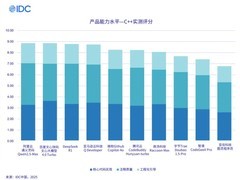
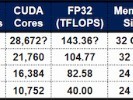
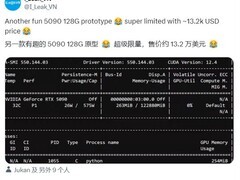
Grok-3强大的性能背后,也引发了人们对训练成本的关注。据马斯克在直播中透露,Grok 3在训练过程中消耗了20万块英伟达GPU,这些训练工作全部都在xAI公司的数据中心完成。有人表示,“我们花了122天才完成了第一个10万卡的训练,但我们并没有就此止步,如果我们想要构建巨型人工智能系统,则需要立即将集群的规模扩大一倍。”
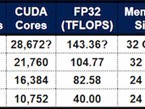
相较于以远低于同行“1/20的成本”训练出堪比OpenAI-01水平R1模型的DeepSeek-v3, Grok-3这一算力消耗的确相当惊人。当马斯克公布Grok-3训练成本后,很快就有专业人士分析指出,“Grok-3的算力消耗是DeepSeek-v3的263倍,中国的人工智能团队只能望洋兴叹。”
如今,在全球范围内使用更加低成本的AI大模型的企业越来越多。这使得昔日专注于研发大模型的机构也开始转变态度,以适应市场需求。然而对于Grok-3而言,其高昂的训练成本和不开源策略可能会成为普及的一大障碍。




















































评论
更多评论