
ZAO 2022中关村在线年度观察推选年度领先解决方案Leading Solutions 30(以下简称LS30),为行业用户提供更好的选择,助力行业优质解决方案与技术方案。
中关村在线认为,2022年AMD推出的RDNA3架构技术可以参与本次终极评选。AMD RNDA3超越了既定目标,实现54%的每瓦性能的提升。从当初的Vega到RDNA,从RDNA到RDNA 2,到RDNA 3,在三代之间实现了超过350%的累计提升。
1 AMD RDNA3 架构浅析
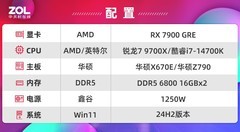
AMD RX 7000系显卡全部采用最新的RDNA3架构,而相比上一代RNDA2架构,有着翻天覆地的变化,并且也是GPU中首次采用大小芯片设计,下面我们来简单剖析一下。
近几年AMD显卡进步神速,这离不开“RDNA”架构的功劳,从初代的RDNA架构到即将发布的RDNA3架构,每年都有大幅提升,而RDNA3相比RX 6000系显卡所使用的RDNA2架构,每瓦性能再次提升54%。
RDNA3架构最大的不同则是采用了双芯片的封装结构,其中更加先进的5nm工艺为主芯片,而较成熟的6nm的制程来打造GDDR 6显存接口,和第二代高速缓存Infinity Cache。
通过Chiplet架构,RDNA 3拥有高达580亿个晶体管。用AMD的话来说,就是用正确的工艺,做正确的工作。
在MCD核心上采用了Memory Cache,每个MCD有64bit的GDDR6的控制器与第二代Infinity Cache。通过Infinity Fabric连接到GCD,可提供2.7倍的峰值带宽,能够支持在更高分辨率下进行游戏。
根据官方说法,全新的Infinity Cache最终有效带宽可达5.3 TB/s,相比初代提升了2.7倍。
在小核心GCD中,由三个全新的单元来组成,第一个是统一的计算单元,第二个是新的显示引擎,第三个是新的双媒体引擎(Dual Media Engine)。
在统一的计算引擎中,图形渲染,人工智能和光线追踪之间能够共享计算资源,提供更高的能耗比和更高的单位面积的性能。
共享的资源包括VGPR——通用的寄存器,容量要比RDNA 2多50%,从而提高了所有功能的性能,能够充分利用这个5nm的制成工艺,在更小的面积当中能够封装出更多的晶体管,增加了165%的密度。
Stream Processor流处理器,采用了双路DualIssue指令分发单元,这使得RDNA3架构能够向Wave32的SIMD Unit发出两路不同的指令,并很好地利用这些数据路径,或者也可以像RDNA 2一样并行的使用。
而通过这样加倍的指令分发能力,可以更好地利用计算单元中所有的功能,然后达成更高的性能,更节能。
RDNA 3的AI功能,提高了常用的AI运算指令的吞吐量,同时将这些运算指令紧密地结合到统一的计算单元当中,提供了超过2.7倍的AI性能的提升,让RDNA 3可以利用当前的硬件单元来实现未来的人工智能要求。
统一的计算单元的最后一项优化是光线追踪,通过新的着色器指令集以及针对ray box sorting(Ray Box排序)和traversal(遍历)多项的优化,让每个计算单元的光追性能能够提高最多50%。
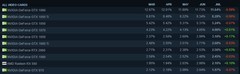
所以在纯渲染方面,RX 7900 XTX是上一代旗舰GPU的1.7倍,在光线追踪方面性能提高了1.6倍。
2 结语
AMD一直在寻求用最合理的方法,提升最大的性能,不冒进。从本次RDNA3架构以及发布的RX 7900 XTX显卡来看,给人最深的印象是——最大化这个概念。
坦白来讲,笔者认为在原有RDNA2架构的基础上修修补补,仍然能够有非常惊人的性能提升,不过代价想必也是功耗的直线提升。
对显卡来说,想要将功耗做高很容易,但以高功耗换来的性能提升,严格来说并不算进步。AMD坚持以每瓦性能来衡量产品的提升,其实是对玩家最负责任的一种解释。
LS30年度领先解决方案具备强大的核心技术和引领产业发展的领导力。依托于技术研发实力、技术创新能力以及技术拓展潜力,不断为用户提供运行速度更快、效能更好且体验更佳的主流应用技术、优质企业商业产品和解决方案,并持续推动产业发展。
























































































































评论
更多评论