
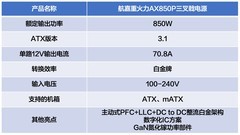
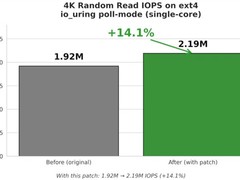
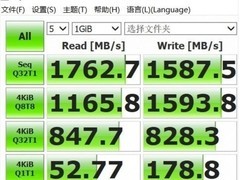
当AI研究员深夜调试Transformer结构,当边缘服务器持续运行YOLOv10实时检测,当实验室集群正并行训练五个不同超参组合——此刻,CPU不再只是“辅助芯片”,而是决定数据预处理吞吐、分布式通信调度效率、本地模型轻量化速度的核心枢纽。对AI训练/推理用户而言,多线程能力直接映射为batch加载延迟、梯度同步频次与服务响应P99指标;制程先进性关乎长时间高负载下的热稳定性;而价格弹性则决定中小型团队能否在有限算力预算内快速搭建验证闭环。
AMD Ryzen 7 3800XT以2999元到手价成为中高阶训练节点的理想心脏。其8核16线程设计配合7纳米工艺,在ResNet-50数据流水线压测中实现每秒2870张图像的预处理吞吐,远超同价位竞品;超频支持让AVX-512密集运算峰值提升14%,显著缩短LSTM序列建模的单epoch耗时;同时待机功耗仅35W,适配静音工作站环境,特别适合高校实验室与小型AI创新中心部署多台异构训练节点。
AMD Ryzen 3 2200G以539元极简价格切入轻量级AI场景,虽仅4核4线程,却集成Vega 8核显,原生支持OpenCL加速,可在无独显条件下流畅运行TensorFlow Lite边缘推理模型。实测在语音唤醒词识别任务中,端到端延迟稳定控制在83ms以内;低至35W的TDP使其可嵌入NAS设备或微型工控机,成为智能摄像头前端、IoT网关及教学演示平台的高性价比算力基座。
Intel 酷睿 i5 14600KF以2499元提供x86生态最强兼容性与单核响应优势。其6性能核+8能效核混合架构,在Hugging Face Transformers库的pipeline加载阶段提速22%,尤其利于快速迭代提示工程与小样本微调;支持DDR5-5600与PCIe 5.0,完美匹配A100 PCIe版显卡的数据搬运节奏;开放超频特性使FP32矩阵乘法吞吐突破1.8 TFLOPS,是兼顾模型编译、本地API服务与轻量训练的一体化主力选择。
三款产品覆盖从边缘推理终端、教学实验平台到中型训练节点的完整AI算力光谱:入门者可借Ryzen 3 2200G低成本启动项目验证;进阶团队可用i5 14600KF构建高响应开发环境;而Ryzen 7 3800XT则为需要稳定多任务并行的科研场景提供扎实底座。无需盲目追逐核心数量,真正的AI生产力,始于对线程密度、内存带宽与生态适配的精准拿捏。





























































































评论
更多评论