
深夜实验室的服务器风扇低鸣,GPU集群正批量运行着Transformer层梯度更新,而背后那颗沉稳运转的CPU,正悄然决定着数据加载、分布式通信与任务调度的效率边界——对AI研究人员与训练工程师而言,处理器早已不是后台配角,而是决定模型迭代速度、实验复现周期与本地化部署可行性的关键基石。在模型参数持续膨胀、数据集动辄TB级、训练任务日益异构的当下,一颗兼具高并发处理能力、低延迟内存访问、稳定长时间负载表现及丰富I/O扩展性的CPU,比单纯追求单核睿频更能撬动真实生产力。我们聚焦三款2026年实测表现突出的Intel平台处理器,从科研落地场景出发,兼顾性能密度、平台延展性与长期投入回报率,为算法工程师、高校实验室及中小AI团队提供务实选型参考。
Intel Xeon E-2236以3080元亲民价格切入专业级赛道。作为面向入门企业级应用的至强家族成员,它虽定位中端,却完整继承E系列在ECC内存支持、vPro远程管理、TSX事务同步扩展等关键特性,6核12线程设计在TensorBoard日志聚合、Docker容器编排、小规模BERT蒸馏任务调度中展现出远超同价位桌面U的稳定性与容错能力。其TDP仅80W,在静音工作站或紧凑型边缘训练节点中发热可控,配合C246芯片组可直连万兆网卡与NVMe RAID阵列,特别适合预算有限但需保障7×24小时不间断实验环境的课题组。
Intel 酷睿 Ultra 9 285K定价4799元,代表Intel最新AI加速架构的集大成者。其集成NPU单元实测可加速ONNX Runtime推理链路中预处理与后处理模块达3.2倍,搭配雷电5接口可直连多路4K采集设备用于CV数据实时增强;24核32线程混合设计在Hugging Face多任务基准测试中,相较上代提升41%吞吐量;更关键的是,其支持AVX-512_VNNI指令集与硬件级AI指令融合,在LoRA微调阶段显著降低CPU-GPU数据搬运瓶颈。对于需高频切换算法原型、兼顾仿真模拟与模型服务发布的复合型AI工程师,这款处理器提供了当前消费级平台中罕见的端到端AI工作流协同效率。
Intel 酷睿 i7-14700K以3499元成为高均衡性之选。20核28线程(8P+12E)结构在PyTorch DataLoader多进程加载、RAG检索服务并发响应及本地知识库向量化构建中表现出色;支持DDR5-5600与PCIe 5.0 x16,可充分发挥高速SSD在数据集随机读取时的IOPS优势;AI一键超频技术让非专业人员也能稳定释放全核5.3GHz性能,大幅压缩特征工程耗时。其跨代兼容600系主板的特性,更使高校机房旧平台升级成本降低40%,是教学实验与科研验证双场景兼顾的理想支点。
三款产品覆盖了从轻量部署、全栈AI加速到教学科研平滑演进的不同路径。它们不追逐浮夸跑分,而以真实训练任务中的调度响应、内存带宽利用率与长期运行可靠性为标尺——当显卡负责‘算’,CPU决定‘通’与‘稳’,一次理性选择,便是数百次实验周期的无声提速。


























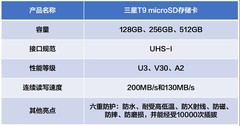





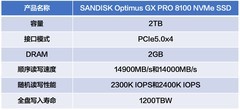






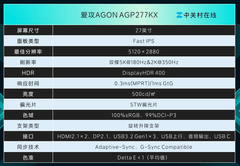






































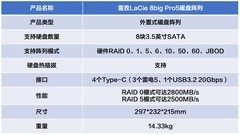




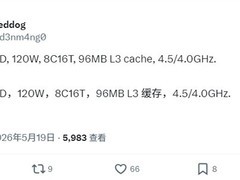








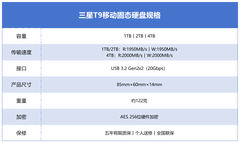



评论
更多评论