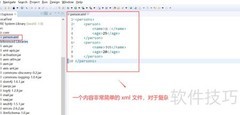
SAX(XML简单应用程序接口)与DOM不同,采用顺序访问模式,是一种高效读取XML数据的方式。使用SAX解析器时,会随着文档的扫描触发一系列事件。每当解析到文档的开始或结束、元素的起始或闭合标签时,系统便会自动调用相应的处理函数,执行预设的操作逻辑。这些事件按文档结构依次发生,处理过程由解析器驱动,逐段进行,无需将整个文档加载到内存中。由于其流式处理机制,SAX特别适用于处理大型XML文件,在节省内存的同时实现快速解析,直至完整遍历并处理完全部内容为止。
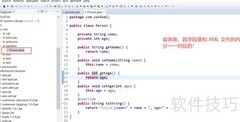
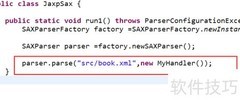
1、 在开发过程中采用SAX解析时,需编写一个继承自DefaultHandler的类作为解析器,重写其中的关键方法。首先实现文档开始与结束的处理逻辑,通过覆盖相应回调方法来完成对XML文档结构的响应,具体定义方式如下所示。
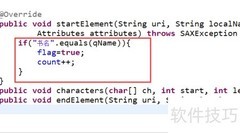
2、 接着定义元素的起始与结束处理方法,用于输出元素名称,并获取该元素的全部属性。通过调用attributes.getQName()获取属性名称,利用attributes.getValue()取得对应属性值,具体实现方式所示。整个过程便于解析和处理XML文档中的标签及其属性信息。
3、 重新编写读取文本节点的方法,获取其全部内容并输出,将字符数组形式的文本转换为字符串类型,具体实现所示。
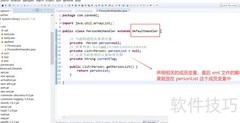
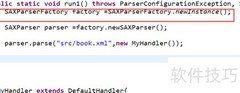
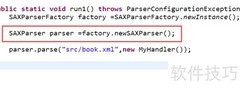
4、 创建SAX解析器后,需构建SAXParserFactory和SAXParser两个对象。首先通过SAXParserFactory的newSAXParser方法获取SAXParser实例,再调用该实例的parse方法,传入待解析的XML文件路径及已定义的SAX解析器,启动解析流程。此过程实现了对XML文档的逐行读取与处理,适用于大文件解析,具有内存占用低、解析效率高的优点,是处理结构化数据的有效方式之一。
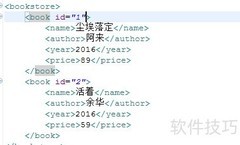
5、 程序运行结果所示。SAX解析采用顺序读取方式,仅加载所需内容,不占用大量内存,因此处理速度快,不受文件大小影响,效率远高于DOM解析。但其只能从头至尾单向解析一次,不支持随机访问或修改节点,在灵活性方面不及DOM解析。






























评论
更多评论