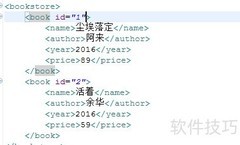
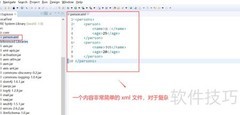
Jaxp的SAX方式采用边读边解析的机制,无需将整个文档载入内存,避免了内存溢出问题,但仅支持查询操作,无法进行修改或写入。
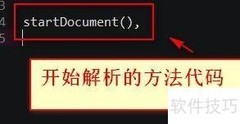
1、 第一步需获取SAX解析器工厂,可通过调用newInstance()方法实现。
2、 通过工厂模式生成SAX解析器实例。
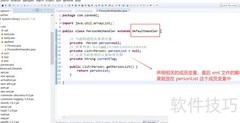
3、 解析器通过调用parse方法处理文档,参数包括资源文件路径path和用户自定义的处理器handler,由开发者编写handler以实现具体解析逻辑。
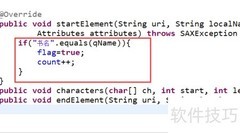
4、 定义一个类继承自DefaultHandler,并重写其中的startElement、characters和endElement方法,这三个方法在解析过程中使用频率较高,分别用于处理元素开始、元素内容和元素结束的事件,是实现XML解析逻辑的关键部分。
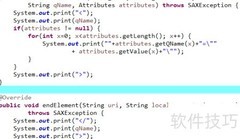
5、 每当解析到开始标签时,系统会自动调用startElement方法,传入命名空间URI、本地名称、限定名以及属性列表等参数,用于处理元素的起始部分,实现对XML文档结构的逐层解析与响应,确保数据的准确读取和处理流程的顺利推进。
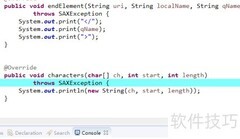
6、 当解析到文本内容时,系统会调用characters方法,该方法包含三个参数:字符数组、起始位置和长度。通过这三个参数,我们可以提取指定范围内的字符并组合成字符串,从而获取完整的文本内容,便于后续处理与使用。
7、 当解析到结束标签时,会触发endElement方法,传入命名空间URI、本地名称和标签名三个参数。与开始标签不同的是,结束标签不包含任何属性信息,因此该方法仅用于标识元素的闭合,不会处理属性相关的内容。
8、 在主方法中调用并运行,检查输出结果是否符合预期。
































评论
更多评论