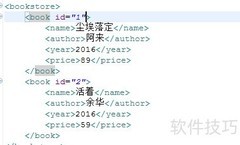
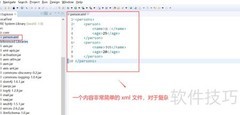
所示的XML中,目标是获取第二本书的书名,采用JAXP中的SAX方式实现解析。
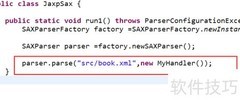
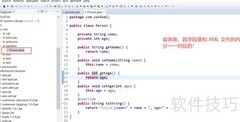
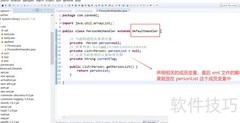
1、 首先创建处理类MyHandler2,继承DefaultHandler,并对其方法进行重写。
2、 三法
3、 定义两个全局变量:flag 与 count。
4、 flag用于标识是否正在解析书名标签。
5、 count用于确定具体是哪一本书。
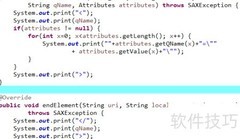
6、 在startElement方法中,通过判断qName是否等于书名,来确定当前解析的元素是否为书名标签。当两者相等时,说明已进入书名标签的开始位置,可进行相应处理。这种方法利用标签名称的字符串比较,实现对特定标签的识别与响应,是解析XML文档结构的重要步骤之一。
7、 当解析到书名标签时,将计数器加一,并将标志设为真。
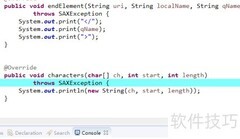
8、 当解析到文本内容时,将调用characters方法,传入字符数组、起始位置和长度参数,用于处理当前文本段的数据。
9、 通过判断flag和count的数值,确定当前是否为第一本书的书名标签。
10、 若是,则输出其内容。
11、 在endElement方法中将flag重新设为false,该操作也可移至上方打印语句之后执行,不影响整体逻辑。根据实际需求选择合适的位置放置该赋值语句,以确保状态控制的准确性和代码的可读性,同时保持对解析过程的有效管理。
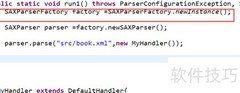
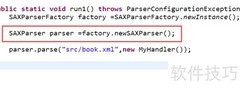
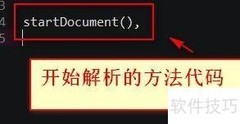
12、 创建SAX工厂和解析器,调用parse方法对XML进行解析。
13、 解析方法需调用前述处理器来实现功能。
14、 运行后观察输出,结果与预期完全相符。

































评论
更多评论