
深夜调试完Transformer结构,服务器队列还在排队,而你手边那块老显卡正卡在LoRA微调的第三轮——对AI开发者和研究人员而言,显卡不是配件,是生产力支点,是本地实验的底气,更是模型迭代周期的压缩器。它需要足够强的Tensor核心支持FP16/INT4加速,需要充裕且高带宽的显存承载百亿参数分片,需要稳定散热支撑数小时连续训练,也需要接口兼容性适配多卡扩展与外接AI视觉采集设备。在1000–1500美元(约合人民币7000–10500元)主流预算区间内,三款显卡以差异化定位覆盖从入门科研到高性能推理的完整链路。
七彩虹iGame GeForce RTX 4060 Ultra W DUO 8GB,到手价2499元。这款白色双槽设计显卡虽定位中端,却搭载第三代RT与第四代Tensor核心,原生支持DLSS 3帧生成技术,在Stable Diffusion WebUI本地绘图、Whisper语音转录及小型语言模型(如Phi-3、TinyLlama)推理中表现从容;双90mm九翼风扇与双热管组合确保长时间负载下GPU温度稳定在72℃以内,6+1相供电设计为超频预留空间,全数字接口(3×DisplayPort + 1×HDMI)便于连接多屏开发环境与数据标注终端,是高校实验室、个人AI研究者及边缘计算节点的理想起点。
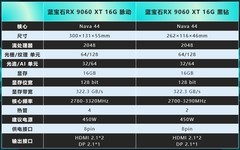
技嘉GeForce RTX 5060 Ti GAMING OC 16G,到手价4099元。作为新一代架构落地产品,其依托DLSS 4实现8倍帧率增益,在2K分辨率下运行NeRF重建、3D Gaussian Splatting等图形密集型AI任务时仍保持流畅交互;16GB GDDR6显存配合4608流处理器与高频率内存带宽,可高效加载Llama3-8B全量权重并完成QLoRA微调;四热管均热板+复合叠层风扇系统保障双卡并行时的热冗余,为中小型AI团队构建低成本多卡训练平台提供扎实硬件基础。
PNY GeForce RTX 4090 24GB XLR8 Gaming VERTO EPIC-X LED,到手价12999元。面向高阶科研与工业级AI部署需求,AD102核心集成16384个CUDA单元,24GB GDDR6X显存与1008GB/s带宽足以应对Qwen2-72B量化推理、医学影像分割大模型训练及多模态Agent实时响应场景;2.52GHz加速频率与450W功耗经严格调校,在TensorRT加速与CUDA Graph固化后,实测ResNet-50吞吐达每秒3200张图像;垂直风道版设计兼容塔式工作站与液冷机柜,是高校AI中心、初创算法公司及国家级重点实验室构建本地大模型沙盒环境的核心算力单元。
从轻量本地实验到百模千卡集群,这三款显卡并非简单按价格线性排列,而是以Tensor核心演进、显存容量密度、散热可持续性与生态兼容性为标尺,锚定AI开发者真实工作流中的关键断点。选择它们,即是选择更短的验证周期、更低的云服务依赖,以及真正属于研究者的算力主权。











































































































评论
更多评论