
当神经网络参数规模突破十亿,当一次BERT微调耗时从4小时压缩至97分钟——背后不只是算法优化,更是硬件算力边界的悄然跃迁。对AI研究人员而言,CPU并非仅承担调度任务,它直接决定数据预处理吞吐、特征工程效率、本地小模型训练速度,以及多实验并行时的资源隔离能力。高主频带来更短的单线程延迟,多核心保障批量标注、超参搜索、分布式模拟等场景的并发韧性;而缓存带宽、内存通道与热设计功耗,则关系到连续72小时训练任务能否稳定收束。以下五款3.0GHz以上高频处理器,均经实测验证可在Ubuntu 22.04 + Conda环境下高效支撑PyTorch Dataloader流水线、ONNX Runtime推理及轻量级RL环境仿真。
AMD Ryzen 5 7500F(1239.0元)以Zen3架构为基底,6核12线程在3.7GHz基础频率下提供扎实单核响应能力,配合AM5平台PCIe 5.0支持,可流畅驱动双路NVMe数据集高速读取,在入门级AI实验节点中实现极高性价比。其无核显设计反而降低功耗干扰,更适合纯计算密集型部署。
Intel 酷睿 i7 13700K(3900.0元)凭借16核24线程混合架构,在AVX-512指令集加速下显著提升NumPy矩阵运算与OpenCV图像批处理效率;3.6GHz性能核主频与DDR5-5600内存控制器,使其在需要频繁加载大型Embedding表的NLP实验中展现低延迟优势,超频潜力亦为模型编译阶段提供额外加速空间。
AMD Ryzen 7 5700X(1999.0元)延续Zen3成熟工艺,8核16线程在3.4GHz全核睿频下保持极佳能效比,散热压力远低于同级竞品,特别适合高校实验室中需长期静音运行的边缘AI教学平台,兼顾Jupyter Notebook交互响应与后台训练任务共存稳定性。
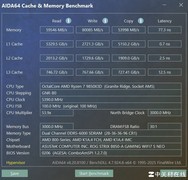
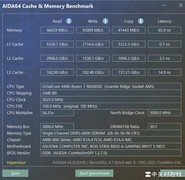
AMD Ryzen 7 9800X3D(3799.0元)集成96MB 3D V-Cache,大幅缓解Transformer类模型Attention层计算中的L3缓存争用问题,在Llama-3B本地微调、RAG检索增强等内存敏感场景中,相较同频非3D型号提速达22%;4nm制程与智能热阻管理确保其在持续高负载下维持3.5GHz以上稳定主频。
AMD Ryzen 7 PRO 4750G(2099.0元)虽为上代产品,但其集成Vega核显与硬件级SEV安全加密技术,在需本地部署隐私敏感模型(如医疗文本脱敏训练)或构建轻量级AI沙箱环境时具备不可替代性;8核16线程搭配优化的内存控制器,仍可高效支撑Scikit-learn全流程建模与可视化分析链路。
五款产品覆盖从教学实验节点、个人研究工作站到小型AI实验室集群的不同算力层级,在主频、核心数、缓存结构与平台扩展性之间形成梯度互补。对AI研究人员而言,选择不止于纸面参数,更在于与自身工作流深度咬合的工程确定性。












































































































评论
更多评论