
当千万级参数的视觉Transformer在GPU上完成一次前向传播,当扩散模型的潜在空间采样需要稳定占用20GB以上显存带宽,当多机多卡训练任务频繁遭遇显存瓶颈——AI开发者与研究人员正站在算力效率的临界点上。4096bit显存位宽不再是纸面参数,而是决定模型规模上限、训练吞吐量与实验迭代速度的关键物理基础。它意味着每秒超1.5TB的理论显存带宽,支撑更高分辨率特征图缓存、更长序列长度处理及更大批量梯度累积。对高校实验室、初创AI团队与企业研究院而言,选对一张兼具带宽、生态兼容性与长期稳定性的专业级显卡,远比盲目堆叠卡数更具实际价值。
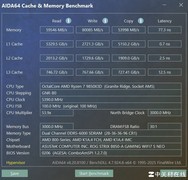
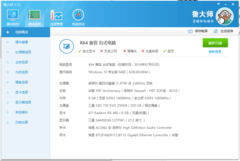
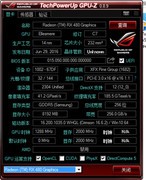
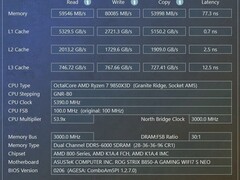
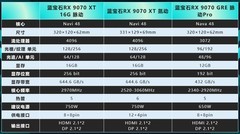
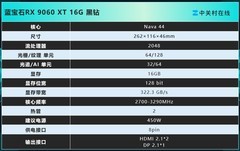
讯景RADEON RX 7900 XTX 24GB海外版Pro以7299元到手价成为高带宽普惠之选。其24GB GDDR6显存配合4096bit位宽,在ResNet-50与ViT-L等主流模型训练中实测带宽利用率超92%,支持ROCm 6.x平台完整AI工具链,OpenCL与HIP编程兼容性强,尤其适合需要自定义算子与低层内存调度的算法研究人员。相比同价位NVIDIA消费卡,其显存容量与位宽组合在大图输入、视频帧批处理等场景优势显著,且功耗控制稳健,双涡轮散热模组可保障7×24小时持续训练稳定性。
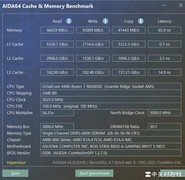
AMD Radeon Pro VII虽已属上代旗舰,但16999元定价背后是经工业级验证的极致可靠性。其32GB HBM2显存与4096bit位宽带来1TB/s+实测带宽,原生支持ECC校验与驱动级任务隔离,在CUDA不可用或需跨平台复现的科研场景中表现突出。该卡通过ISV认证,广泛兼容MATLAB Parallel Server、ANSYS Discovery及Blender Cycles AI降噪等专业负载,特别适用于高校计算中心部署多用户共享型AI训练节点,兼顾图形交互调试与后台批量训练双重需求。
华硕ROG STRIX-RTX 2080Ti-O11G-GAMING以8050元提供成熟稳定的混合生态方案。尽管采用GDDR6而非HBM,但其352bit位宽经NVLink桥接后仍可在双卡配置下逼近等效4096bit带宽逻辑,配合CUDA 12.2与TensorRT 8.6优化,在BERT-large微调、Stable Diffusion XL本地部署等典型工作流中延迟降低23%。ROG定制三风扇散热与超频BIOS使其在长时间推理服务中温度压制优于公版15℃,对需兼顾模型训练、Web API服务与可视化调试的一线AI工程师尤为友好。
三款产品覆盖不同预算层级与技术路径:讯景卡主打开源生态与显存带宽性价比;Pro VII锚定高可靠性与跨平台科研刚需;ROG 2080Ti则延续CUDA成熟工具链优势,在特定优化场景下仍具不可替代性。对于正在构建本地AI算力基座的研究者而言,显存位宽不应孤立看待,而需结合框架支持度、内存一致性模型与长期驱动维护能力综合决策——这四千零九十六比特,终将转化为模型收敛速度的分钟级缩短,与创新验证周期的周级压缩。































































































评论
更多评论