
四月三日,微软正加快自主研发人工智能模型的进程,计划在未来数年内构建具备国际领先水平的通用AI系统,以与全球头部模型研发机构展开技术竞争。
微软人工智能业务负责人穆斯塔法·苏莱曼表示,公司必须持续突破模型性能边界,明确将二零二七年设定为关键节点——届时在文本理解、图像生成及音频处理等核心能力上,全面达到业界最高水准。
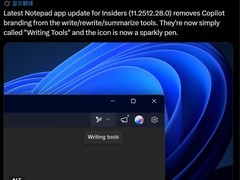
作为阶段性进展,微软于四月二日推出一款专注于语音转录任务的专用模型。该模型支持二十五种主流语言,在其中十一种语言的基准测试中展现出优于同类产品的识别精度。其设计定位强调运行效率与部署轻量性,与当前主流通用大模型在技术路径与应用场景上存在显著区分。
在底层算力支撑方面,微软正加速推进新一代基础设施建设。苏莱曼介绍,公司已启动英伟达GB200芯片集群的规模化部署,并将在未来十二至十八个月内完成算力资源的前沿级升级。
此前,微软在通用大模型研发领域受到既有合作框架的约束。随着去年相关协议完成优化调整,公司在模型自主开发方面的权限获得实质性拓展,技术路线的独立性由此得到保障。
组织架构层面亦同步优化:苏莱曼目前全面聚焦于基础模型的研发工作;而Copilot相关产品线则由前Snap高管雅各布·安德鲁牵头负责。
微软首席执行官萨提亚·纳德拉在本周举行的内部战略会议上指出,未来三至五年实现AI核心技术能力的全面自主可控,是公司最重要的战略方向之一。与此同时,对多元外部模型生态的支持与协同仍将延续。
据悉,本次发布的语音转录模型具备强鲁棒性,在嘈杂、混响等复杂声学环境下可有效抑制背景干扰,后续将分阶段集成至Teams等办公协作产品中,提升实际使用体验。






































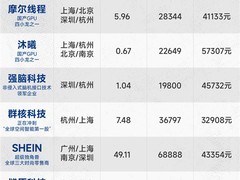










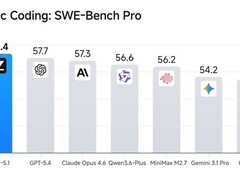



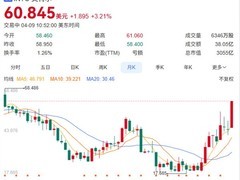
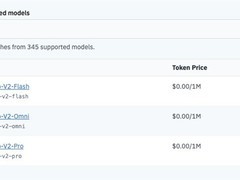








评论
更多评论