
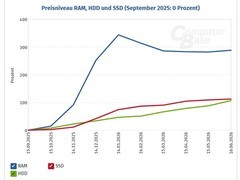
当模型参数突破十亿、数据集规模跃升至TB级,当研究者在深夜调试Transformer结构却遭遇显存溢出警告——一张兼具高带宽、低延迟与架构前瞻性的8GB显卡,早已不是配件,而是科研节奏的节拍器。面向AI开发者与前沿研究人员,显存容量仅是起点,真正决定实验迭代速度的是显存带宽、计算精度支持、多任务隔离能力及软硬件协同生态。本批次精选三款定位分层、场景互补的8GB显卡,覆盖从高校实验室到企业AI平台的不同算力需求。
NVIDIA Tesla A100 80G虽标称80GB,但其核心价值在于为8GB级模型提供超规格加速底座:基于GA100核心的6912 CUDA单元与第三代Tensor Core,配合2039 GB/s HBM2e带宽,在FP16混合精度下实现超150 TFLOPS张量算力;独有MIG(多实例GPU)技术可将单卡切分为7个独立GPU实例,满足多个学生课题组并行训练小模型的需求;NVLink支持4卡无损互联,构建低成本小型集群;对于需频繁验证稀疏化、量化策略的研究者,其原生结构化稀疏指令集大幅缩短算法验证周期。尽管售价达86999元,但在需要稳定支撑ResNet-152全参训练、BERT-large微调及强化学习环境仿真等中等规模任务的科研场景中,其单位算力成本与长期运维稳定性极具优势。
七彩虹iGame GeForce RTX 4060 Ultra W DUO 8GB以2499元精准锚定入门级AI开发节点:采用Ada Lovelace架构,支持DLSS 3帧生成与Reflex低延迟技术,在图像分割、目标检测等CV任务的原型验证阶段表现稳健;8GB GDDR6显存搭配128-bit位宽虽非极致,但足以运行YOLOv8s、EfficientNet-B0等主流轻量模型;双风扇散热与300W功耗设计使其轻松嵌入常规工作站机箱,特别适合研究生个人实验平台或边缘端模型优化测试环境。其CUDA核心数量与Tensor Core代际特性,亦保障了对PyTorch 2.x新特性的完整兼容。
技嘉GeForce RTX 5060 WINDFORCE 8G则代表下一代生产力入口:Blackwell架构下3840 CUDA核心与2497MHz高频,结合8GB高速GDDR7显存(等效28Gbps),在128-bit位宽约束下仍实现远超前代的每瓦性能比;PCIe 5.0接口降低数据加载瓶颈,DP 2.1b多屏输出便于监控训练曲线与可视化调试;对需在本地快速迭代LoRA适配器、进行语音模型实时推理的开发者而言,其能效比与API响应一致性显著优于同价位竞品。2499元定价使其成为高校AI课程实训平台与中小企业算法工程师日常开发机的理想选择。
三款产品并非简单替代关系,而是构成梯度清晰的AI算力拼图:A100承载科研攻坚,RTX 4060夯实工程基础,RTX 5060预演未来范式。无论身处顶级实验室还是初创团队,一套契合当前任务复杂度、预留升级路径且严控TCO的显卡配置,终将让每一次forward pass都更接近答案。






































































































评论
更多评论