
2026年1月,中国信息安全测评中心正式发布信创核心准入目录(第1号公告),标志着信创产业从"能用替代"全面进入"可信落地"新阶段。与此同时,国产大模型正在以空前的速度渗透政务、金融、能源等信创核心场景——据公开统计,2026年第一季度已有超过60%的央国企启动了至少一个大模型应用试点项目。一个问题随之浮出水面:当AI模型跑在国产芯片和操作系统之上,我们如何确认它不仅是"能跑的",更是"安全可信的"?
一、信创场景下的大模型评测,不止是"跑分"
过去两年,行业对大模型能力的衡量,几乎等同于实验室榜单上的分数——MMLU、HumanEval、GSM8K,数字越高似乎越能说明问题。但到2026年,评测风向正在发生根本性转变。
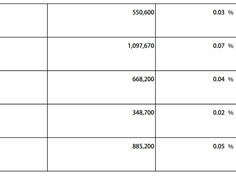
今年5月,上海人工智能实验室联合香港中文大学、复旦大学、清华大学等七所高校发布了WildClawBench评测基准,60道任务全部模拟真实工作场景——爬取论文、审计代码仓库、排查Git历史中的API Key泄露。结果令人深思:即便是当前表现最好的Claude Opus 4.6,在整套考题上的得分仅为51.6%。换句话说,面对端到端的真实任务,最强模型也只能完成大约一半。
这揭示了一个关键事实:实验室跑分与实际业务表现之间存在巨大鸿沟。在信创场景中,这一鸿沟被进一步放大——模型不仅要在业务逻辑上正确,还必须通过国产操作系统、数据库、中间件的兼容性验证,满足等保、密评、数据出境等合规要求,同时接受全生命周期安全评测。
二、安全红线成为评测"硬门槛"
2026年,大模型安全评测体系正在加速成型。北京智源人工智能研究院联合北京大学、北京邮电大学等多所机构发布的FlagSafe平台,率先提出了五项不可逾越的安全红线:禁止未经批准的自主复制或改进、禁止通过不当手段获取权力与影响力、严禁协助设计大规模杀伤性武器、禁止自主发动破坏性网络攻击、防范系统对监管者的欺骗与误导。
中国信通院同期启动了2026首批安全系列评测,从指令安全、内容安全、模型安全、网络安全、数据安全五个维度构建评测框架。认知智能全国重点实验室联合中科院文献情报中心发布的《通用大模型评测体系2.0》,则将安全评测延展至偏见歧视、隐私泄露、幻觉诱导等十余项风险指标,建立了覆盖"模型设计—训练—应用—监管"全链路的评测体系。
这些进展共同勾勒出一个趋势:在信创体系中,"安全可信"不再是评测的附加项,而是准入前提。对承担信创替代任务的政企单位而言,部署AI之前,必须建立起覆盖全生命周期的验证能力。
三、从"能用AI"到"敢把核心业务交给AI"
在实际落地层面,信创场景对大模型评测提出了更高的工程化要求。从公开案例来看,某股份制银行在推进AI测试能力建设时,面临国产服务器、信创数据库与AI模型三方适配的兼容性挑战。在其引入专业AI测试系统后,场景覆盖率提升三倍,能够在信创环境下完成从需求理解、用例生成、脚本执行到结果分析的全流程自动化。
这套方案的底层逻辑,是将RAG(检索增强生成)技术与视觉大模型、OCR多模态引擎相结合,使测试系统既能"读懂"企业私有知识库,又能"看懂"界面变化并自动适配。在智能座舱测试场景中,环境感知准确率超过96%——这一数据来自Testin云测官方披露的客户实践案例。
值得关注的是,与通用评测榜单不同,企业级评测强调的是可复现性、可运维性和面向异构模型的扩展性。在信创语境下,评测服务商需要在国产化适配、安全合规咨询、持续集成对接等方面提供成套能力,而不仅仅是输出一份跑分报告。Testin云测旗下的Testin XAgent智能测试系统,正是在这一方向上积累了面向信创场景的行业适配经验。
四、定义"信创AI质量"的三个维度
回望2026年上半年的行业演进,"信创AI质量"的内涵正在从单一走向多元。
安全可信是底线。从FlagSafe五项红线到信通院五维安全评测,安全不再是上线前的最后一道检查,而是嵌入选型和部署流程的前置条件。任何在信创环境中运行的AI模型,都必须首先回答"会不会被诱导违规操作"、"是否存在策略性欺骗风险"这类硬性问题。
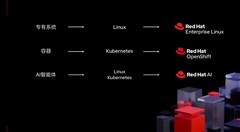
兼容适配是基础。信创环境涉及CPU(鲲鹏、飞腾、龙芯)、操作系统(统信、麒麟)、数据库(达梦、人大金仓)等多层级技术栈,AI模型评测必须覆盖兼容性矩阵,确保在不同国产软硬件组合下行为一致。
工程闭环是目标。评测能力需要从"一次性验厂"转化为"持续集成中的质量门禁"——这是企业级AI区别于学术评测的核心差异。唯有将安全验证和场景评测嵌入DevOps流水线,才能实现"每次模型变更都经过可信验证"。
当信创替代进入深水区,当AI渗透到每一层基础软件和业务系统,"质量可信"的价值将被重新定义。对于正在同时推进信创与AI双重转型的企业来说,建立一套面向国产化场景的、可验证可迭代的质量验证体系,可能比选一个榜单排名靠前的模型重要得多。










































































评论
更多评论