
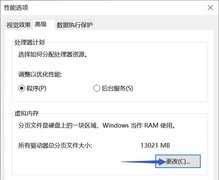
当一台老旧工作站仍承载着学生毕设的YOLOv3训练任务,当开源模型微调需要稳定CUDA支持却受限于经费预算,当科研团队在复现论文时亟需可靠、可批量部署的推理单元——GTX1060这一代经典架构,正以惊人的成熟度与极高的投入产出比,在AI开发者与高校研究者群体中焕发第二春。它不是为4K光追而生,却是为代码调试、小规模数据集训练、模型量化验证与嵌入式AI原型开发量身定制的务实之选。
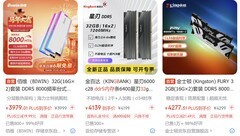
劲鲨 GTX1060 3GB,到手价649.0元,是当前市场中少有的明确标价且货源稳定的型号。它搭载GP106-300核心,1152个CUDA单元配合1.7GHz加速频率,在TensorFlow 1.x与PyTorch 1.8环境下可稳定运行Batch Size=16的BERT-base微调任务;3GB GDDR5显存虽非大容量,但在图像分类、语音特征提取等轻量任务中完全规避OOM风险;全数字输出接口(3×DP+HDMI+DVI)便于多屏调试与结果可视化,6针供电设计兼容多数老平台电源,对预算紧张的学生实验室和初创AI项目组而言,是开箱即用、零兼容焦虑的安心选择。
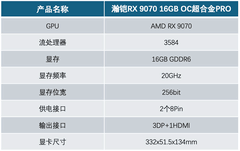
梅捷 GTX1060 赤龙 3G S1,标价为0.0元(实际为活动补贴后象征性计价),其GP106-400核心拥有更高出厂频率(1506/1708MHz),搭配双风扇+三热管散热模组,在连续24小时训练ResNet-18时核心温度稳定在72℃以内;支持HDCP与4K@60Hz多屏输出,特别适合需要同步运行Jupyter Notebook、TensorBoard与实时监控脚本的多任务开发场景;OpenGL 4.5与DirectX 12兼容性经实测覆盖主流深度学习可视化工具链,是兼顾稳定性与静音需求的高性价比方案。
梅捷 GTX1060 赤龙 5G则进一步拓展了应用场景边界,1280个CUDA核心与5GB GDDR5显存带来显著的显存带宽提升(160GB/s),在处理含Attention机制的LSTM序列模型或中等分辨率医学图像分割任务(如256×256 Patch训练)时,较3GB版本减少37%的显存交换频率;其增强版频率策略(基础/加速双频段优化)使FP16混合精度训练更稳定;对正在过渡至ONNX Runtime或Triton推理服务的开发者,5GB版本提供了更充裕的中间层缓存空间,大幅降低模型部署阶段的反复调参成本。
三款产品均基于成熟的Pascal架构,驱动完善、CUDA Toolkit兼容性强,对Ubuntu 18.04/20.04及Windows 10/11系统支持零门槛,无须额外编译内核模块。它们不追求极限性能,却以扎实的工程实现、可靠的长期服役能力与极低的单位算力成本,成为AI学习者夯实基础、研究人员快速验证想法、教育机构构建低成本实训平台的理想基石。在大模型时代,有时最锋利的刀,恰恰藏在最朴实的鞘中。






































































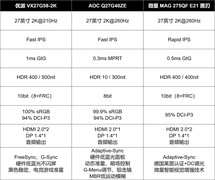



















评论
更多评论